J.U.C
J.U.C是java.util.concurrent的简写,里面提供了很多线程安全的集合。
- CopyOnWriteArrayList
- CopyOnWriteArraySet
- ConcurrentSkipListSet
- ConcurrentHashMap
- ConcurrentSkipListMap
- BlockingQueue
- BlockingDeque
CopyOnWriteArrayList
介绍
CopyOnWriteArrayList相比于ArrayList是线程安全的,字面意思是写操作时复制。CopyOnWriteArrayList使用写操作时复制技术,当有新元素需要加入时,先从原数组拷贝一份出来。然后在新数组里面加锁添加,添加之后,将原来数组的引用指向新数组。
1 | public boolean add(E e) { |
从上面的源码中得到CopyOnWriteArrayList的add操作是在加锁的保护下完成的。加锁是为了多线程对CopyOnWriteArrayList并发add时,复制多个副本,把数据搞乱。
1 | public E get(int index) { |
以上代码显示
get是没有加锁的如果出现并发
get,会有以下3种情况。
- 如果写操作未完成,那么直接读取原数组的数据;
- 如果写操作完成,但是引用还未指向新数组,那么也是读取原数组数据;
- 如果写操作完成,并且引用已经指向了新的数组,那么直接从新数组中读取数据。
使用场景
- 由于在
add的时候需要拷贝原数组,如果原数组内容比较多,比较大,可能会导致young gc和full gc。 - 不能用于实时读的场景,像拷贝数组,新增元素都需要时间,所以调用
get操作后,有可能得到的数据是旧数据,虽然CopyOnWriteArrayList能做到最终一致性,但是没有办法满足实时性要求。 CopyOnWriteArrayList适合读多写少的场景,比如白名单,黑名单等场景CopyOnWriteArrayList由于add时需要复制数组,所以不适用高性能的互联网的应用。
CopyOnWriteArraySet
介绍
1 | public CopyOnWriteArraySet() { |
CopyOnWriteArraySet底层是用CopyOnWriteArraySet来实现的。可变操作(add,set,remove等)都需要拷贝原数组进行操作,一般开销很大。迭代器支持hasNext(),netx()等不可变操作,不支持可变的remove操作,使用迭代器速度很快,并且不会与其它线程冲突,在构造迭代器时,依赖不变的数组快照。
使用场景
- 适用于set大小一般很小,读操作远远多于写操作的场景
ConcurrentSkipListSet
介绍
1 | public ConcurrentSkipListSet() { |
ConcurrentSkipListSet<E>是jdk6新增的类,支持自然排序,位于java.util.concurrent。ConcurrentSkipListSet<E>都是基于Map集合的,底层由ConcurrentSkipListMap实现。
在多线程环境下,ConcurrentSkipListSet<E>的add,remove,contains是线程安全的。但是对于批量操作addAll,removeAll,containsAll并不能保证原子操作,所以是线程不安全的,原因是addAll,removeAll,containsAll底层调用的还是add,remove,contains方法,在批量操作时,只能保证每一次的add,remove,contains是原子性的(即在进行add,remove,contains,不会被其它线程打断),而不能保证每一次批量操作都不会被其它线程打断,因此在addAll、removeAll、retainAll 和 containsAll操作时,需要添加额外的同步操作。
1 | public boolean addAll(Collection<? extends E> c) { |
ConcurrentHashMap
ConcurrentHashMap中key和value都不允许为null,ConcurrentHashMap针对读操作做了大量的优化。在高并发场景很有优势。
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率到100%,所以在多线程环境不能随意使用HashMap。原因分析:HashMap在进行put的时候,插入的元素超过了容量就会发生rehash扩容,这个操作会把原来的元素hash到新的扩容新的数组,在多线程情况下,如果此时有其它线程在进行put操作,如果Hash值相同,可能出现在同一数组下用链表表示,造成闭环,导致get的时候出现死循环,所以是线程不安全的。
HashTable它是线程安全的,它涉及到多线程的操作都synchronized关键字来锁住整个table,这就意味着所有的线程都在竞争同一把锁,在多线程环境下是安全的,但是效率很低。
HashTable有很多的优化空间,锁住整个table这么粗暴的方法可以变相的柔和点,比如在多线程的环境下,对不同的数据集进行操作时其实根本就不需要去竞争一个锁,因为他们不同hash值,不会因为rehash造成线程不安全,所以互不影响,这就是锁分离技术,将锁的粒度降低,利用多个锁来控制多个小的table,多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMapJDK1.7版本的核心思想。
不能为null原因:
The main reason that nulls aren’t allowed in ConcurrentMaps (ConcurrentHashMaps, ConcurrentSkipListMaps) is that ambiguities that may be just barely tolerable in non-concurrent maps can’t be accommodated. The main one is that if map.get(key) returns null, you can’t detect whether the key explicitly maps to null vs the key isn’t mapped.
In a non-concurrent map, you can check this via map.contains(key),but in a concurrent one, the map might have changed between calls.Further digressing: I personally think that allowing
nulls in Maps (also Sets) is an open invitation for programs
to contain errors that remain undetected until
they break at just the wrong time. (Whether to allow nulls even
in non-concurrent Maps/Sets is one of the few design issues surrounding
Collections that Josh Bloch and I have long disagreed about.)It is very difficult to check for null keys and values
in my entire application .
Would it be easier to declare somewhere
static final Object NULL = new Object();
and replace all use of nulls in uses of maps with NULL?-Doug
ConcurrentSkipListMap
ConcurrentSkipListMap内部使用SkipList结构实现。跳表是一个链表,但是通过跳跃式的查找方式使得插入,读取数据时的时间复杂度变成O(log n)。
跳表(SkipList):使用空间换时间的算法,令链表的每个结点不仅记录next结点位置,还可以按照level层级分别记录后继第level个结点。
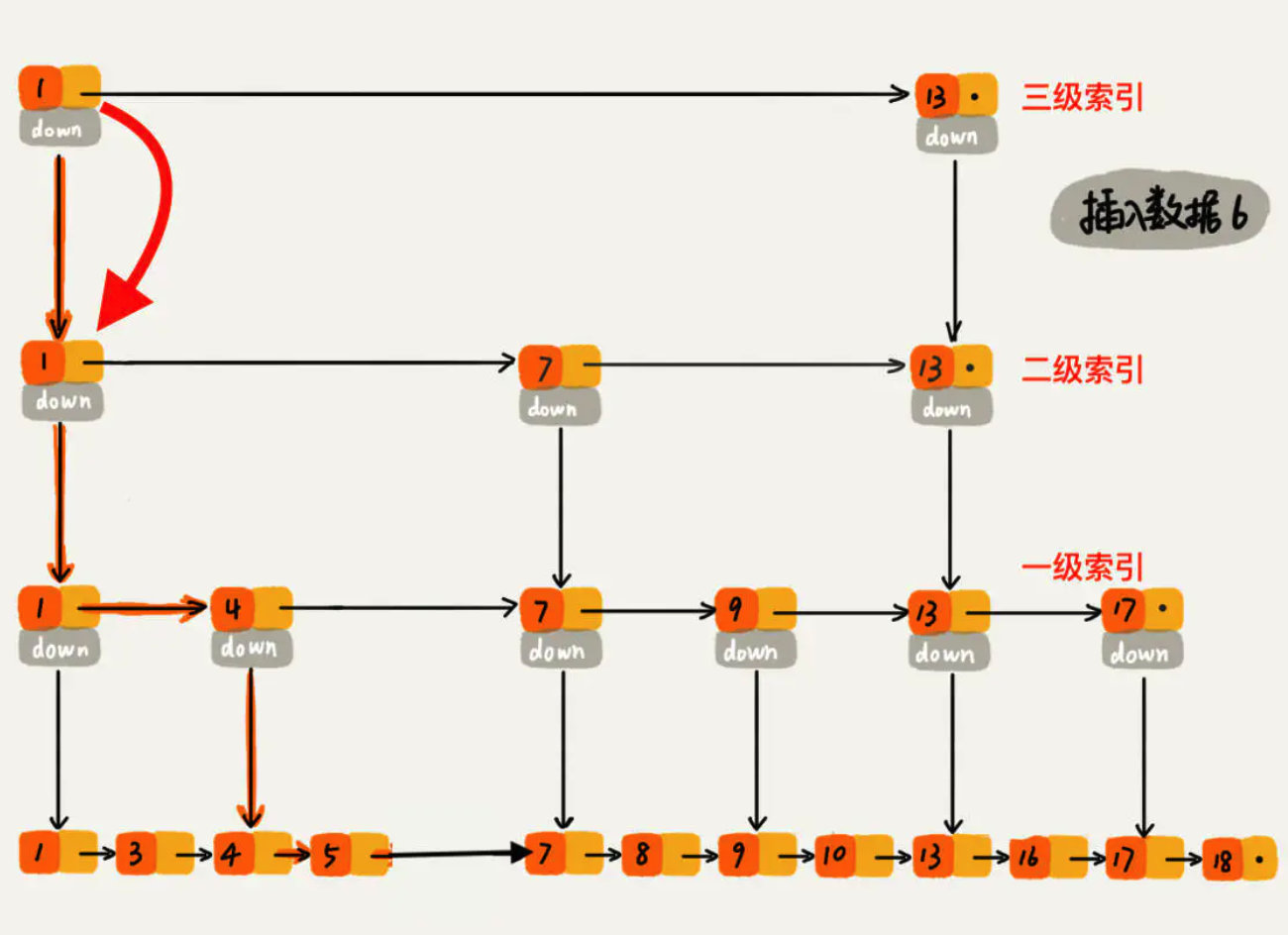
ConcurrentHashMap与ConcurrentSkipListMap的对比
ConcurrentHashMap比ConcurrentSkipListMap性能要好一些。ConcurrentSkipListMap的key是有序的,ConcurrentHashMap做不到。ConcurrentSkipListMap支持高并发,它的时间复杂度是log(N),和线程数无关,也就是说任务一定的情况下,并发的线程越多,ConcurrentSkipListMap的优势就越能体现出来。
BlockingQueue
多线程中通过队列很容易共享数据,比如经典的
生产者和消费者模型中,通过队列可以很方便的实现数据共享。假设我们有若干生产者线程,又有若干消费者线程,生产者线程可以通过队列将数据共享给消费者。但是生产者和消费者在某个时间段内,万一发生数据处理速度不匹配的情况呢?如果生产者生产数据的速度远大于消费者消费数据的速度,理想情况下是当生产者产生的数据到达一个阈值之后,那么生产者必须暂停一下(阻塞生产者线程),以便消费者可以把数据消费掉。在concurrent包出现之前,开发人员必须手动控制这些细节,导致开发高性能程序难度较大(兼顾效率和安全)。concurrent出来之后,带来了BlockingQueue(在多线程中,在某些情况下挂起线程(即阻塞),一旦条件满足,被挂起的线程又会被自动唤醒)
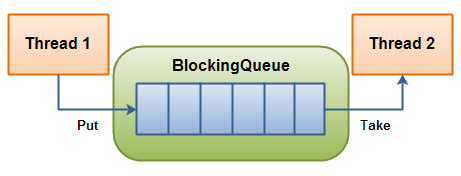
BlockingQueue即为阻塞队列,是一个先进先出的队列,在某些情况下,对阻塞队列的访问可能会造成阻塞,被阻塞的情况主要有两种。
- 当对列满时,进行入队操作时。当一个线程试图对一个已经满了的队列进行入队操作时,也将会被阻塞,除非有一个线程进行了出队列操作。
- 当队列空时,进行出队操作时。当一个线程试图对一个为空的队列进行出队列操作时,也将会被阻塞,除非有一个线程进行了出队列操作。
阻塞队列是线程安全的,主要用在生产者消费者的场景上。负责生产的线程不断的制造新对象并插入到阻塞队列中,直到到达队列的上限值,从而被阻塞,直到消费线程对队列进行消费。同理,负责消费的线程不断的从队列中取出对象进行消费,直到这个队列为空,这时消费队列会被阻塞,除非队列中有新的对象被加入进来。
1 | public interface BlockingQueue<E> extends Queue<E> {} |
BlockingQueue是一个接口,继承自Queue,所以实现类也可以作为Queue的实现来使用,而Queue又继承自Collection接口。
BlockingQueue对插入操作,移除操作,获取元素操作提供了四种不同的方法用于不同的场景,使用不同的方法,会有不同的效果。BlockingQueue的各个实现都遵循这些规则。
| Throws Exception | Special Value | Blocks | Times Out | |
|---|---|---|---|---|
| insert | add(o) | offer(o) | put(o) | offer(o,timeout,timeunit) |
| remove | remove(o) | poll() | take() | poll(timeout,timeunit) |
| examine | element() | peek() | not applicable | not applicable |
- Throws Exception:抛出异常。如果不能马上进行,则抛出异常。
- Special Value:如果不能马上进行,则返回特殊值,一般是True或False
- Blocks:如果不能马上进行,则操作会被阻塞,直到这个操作成功
- Times Out:如果不能马上进行,操作会被阻塞指定的时间。如果指定时间还未执行,则返回特殊值,一般是True或False。
对于
BlockingQueue,关注点应该在它的put和take方法上,因为这两个方法是带阻塞。
BlockingQueue不接受null值的插入,相应的方法在碰到null的插入时会抛出NullPointerException异常,null值通常用于特殊值返回(表格中的第三列),代表poll失败。所以如果允许插入null值的话,那获取的时候,就不能很好的用null来判断到底是失败还是获取的值为null。
BlockingQueue实现了java.util.Collection接口,我们可以使用remove(x)来删除任意一个元素,但是这类操作并不高效,所以尽量在少数场合使用,比如一条消息已经入队,但是需要取消操作的时候。
BlockingQueue的实现都是线程安全的,但是批量的集合操作addAll,containsAll,retainAll,removeAll不一定是原子操作,如addAll(c)添加了一些元素后抛出异常,此时BlockingQueue中已经添加了部分元素,这个是允许的,取决于具体实现。
BlockingQueue在生产者-消费者的场景中,是支持多消费者和多消费者的,说的其实就是线程安全问题。BlockingQueue是一个比较简单的线程安全容器。作为BlockingQueue的使用者,我们再不用考虑何时阻塞线程,什么时候唤醒线程,因为这一些BlockingQueue都实现了。
无界队列,并不是大小不限制,只是它的大小是Integer.MAX_VALUE,即int类型能表示的最大值(2的31次方)-1
BlockingQueue具体实现类
- ArrayBlockingQueue
- LinkedBlockingQueue
- DelayQueue
- PriorityBlockingQueue
- SynchronousQueue
常用的是
ArrayBlockingQueue和LinkedBlockingQueue
BlockingQueue重要的实现类
ArrayBlockingQueue
有界的阻塞队列,内部是一个数组,有边界的意思是:容量是有限的,必须进行初始化,指定它的容量大小,以先进先出的方式存储数据,最新插入的在对尾,最先移除的对象在头部。
1 | public class ArrayBlockingQueue<E> extends AbstractQueue<E> |
ArrayBlockingQueue在生产者放入数据和消费者获取数据,都是共用一个锁对象,由此也意味着两者无法真正并行运行。按照实现原理来分析,ArrayBlockingQueue完全可以采用分离锁,从而实现生产者和消费者操作的完全并行运行。然而事实上并没有如此,因为ArrayBlockingQueue的数据写入已经足够轻巧,以至于引入独立的锁机制,除了给代码带来额外的复杂性外,其在性能上完全占不到任何便宜。- 通过构造函数得知,参数
fair控制对象内部是否采用公平锁,默认采用非公平锁。 items、takeIndex、putIndex、count等属性并没有使用volatile修饰,这是因为访问这些变量(通过方法获取)使用都在锁内,并不存在可见性问题,如size()。- 另外有个独占锁
lock用来对出入对操作加锁,这导致同时只有一个线程可以访问入队出队。
Put源码分析
1 | /** 进行入队操作 */ |
这里由于在操作共享变量前加了锁,所以不存在内存不可见问题,加锁后获取的共享变量都是从主内存中获取的,而不是在CPU缓存或者寄存器里面的值,释放锁后修改的共享变量值会刷新到主内存。
另外这个队列使用循环数组实现,所以在计算下一个元素存放下标时候有些特殊。另外
insert后调用notEmpty.signal();是为了激活调用notEmpty.await();阻塞后放入notEmpty条件队列的线程。
Take源码分析
1 | public E take() throws InterruptedException { |
Take操作和Put操作很类似
1 | //该类的迭代器,所有的迭代器共享数据,队列改变会影响所有的迭代器 |
Itrs迭代器创建的时机
1 | //从这里知道,在ArrayBlockingQueue对象中调用此方法,才会生成这个对象 |
LinkedBlockingQueue
基于链表的阻塞队列,通
ArrayBlockingQueue类似,其内部也维护这一个数据缓冲队列(该队列由一个链表构成),当生产者往队列放入一个数据时,队列会从生产者手上获取数据,并缓存在队列的内部,而生产者立即返回,只有当队列缓冲区到达最大值容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞队列,直到消费者从队列中消费掉一份数据,生产者会被唤醒,反之对于消费者这端的处理也基于同样的原理。
LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行的操作队列中的数据,以调高整个队列的并发能力。如果构造一个
LinkedBlockingQueue对象,而没有指定容量大小,LinkedBlockingQueue会默认一个类似无限大小的容量Integer.MAX_VALUE,这样的话,如果生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就有可能已经被消耗殆尽了。
LinkedBlockingQueue是一个使用链表完成队列操作的阻塞队列。链表是单向链表,而不是双向链表。
1 | public class LinkedBlockingQueue<E> extends AbstractQueue<E> |
通过其构造函数,得知其可以当做无界队列也可以当做有界队列来使用。
这里用了两把锁分别是
takeLock和putLock,而Condition分别是notEmpty和notFull,它们是这样搭配的。
- 如果需要获取(take)一个元素,需要获取
takeLock锁,但是获取了锁还不够,如果队列此时为空,还需要队列不为空(notEmpty)这个条件(Condition)。 - 如果要插入(put)一个元素,需要获取
putLock锁,但是获取了锁还不够,如果队列此时已满,还是需要队列不满(notFull)的这个条件(Condition)。
从上面的构造函数中可以看到,这里会初始化一个空的头结点,那么第一个元素入队的时候,队列中就会有两个元素。读取元素时,也是获取头结点后面的一个元素。count的计数值不包含这个头结点。
Put源码分析
1 | public class LinkedBlockingQueue<E> extends AbstractQueue<E> |
Take源码分析
1 | public class LinkedBlockingQueue<E> extends AbstractQueue<E> |
与ArrayBlockingQueue对比
ArrayBlockingQueue是共享锁,粒度大,入队与出队的时候只能有1个被执行,不允许并行执行。LinkedBlockingQueue是独占锁,入队与出队是可以并行进行的。当然这里说的是读和写进行并行,两者的读读与写写是不能并行的。总结就是LinkedBlockingQueue可以并发读写。
ArrayBlockingQueue和LinkedBlockingQueue间还有一个明显的不同之处在于,前者在插入或删除元素时不会产生或销毁任何额外的对象实例,而后者则会生成一个额外的Node对象。这在长时间内需要高效并发地处理大批量数据的系统中,其对于GC的影响还是存在一定的区别。
DelayQueue
DelayQueue是一个无界阻塞队列,只有在延迟期满时才能从中提取元素。该队列的头部是延迟期满后保存时间最长的Delayed元素。
存放到DelayDeque的元素必须继承Delayed接口。Delayed接口使对象成为延迟对象,它使存放在DelayQueue类中的对象具有了激活日期,该接口强制执行下列两个方法:
- CompareTo(Delayed o):Delayed接口继承了Comparable接口,因此有了这个方法
- getDelay(TimeUnit unit):这个方法返回到激活日期的剩余时间,时间单位由单位参数指定
DelayQueue使用场景
- 关闭空闲链接。服务器中,有很多客户端链接,空闲一段时间
SynchronousQueue
它是一个特殊的队列交做同步队列,特点是当一个线程往队列里写一个元素,写入操作不会理解返回,需要等待另外一个线程来将这个元素拿走。同理,当一个读线程做读操作的时候,同样需要一个相匹配写线程的写操作。这里的
Synchronous指的就是读写线程需要同步,一个读线程匹配一个写线程,同理一个写线程匹配一个读线程。不像
ArrayBlockingQueue、LinkedBlockingDeque之类的阻塞队列依赖AQS实现并发操作,SynchronousQueue直接使用CAS实现线程的安全访问。较少使用到 SynchronousQueue 这个类,不过它在线程池的实现类 ScheduledThreadPoolExecutor 中得到了应用。
1 | public class SynchronousQueue<E> extends AbstractQueue<E> |
BlockingDeque
BlockingDeque接口和BlockingQueue接口一样都是在java.util.concurrent中定义的,它代表了一个线程安全的“双端队列”,以线程安全的方式向队列中添加元素或获取元素。
deque是 “Double Ended Queue “的缩写。因此“双端队列”的含义就是可以从两端(队首或队尾)插入和取出元素的队列。
如果某个线程既生产又消费同一个队列的元素,那么就可以使用BlockingDeque双端队列。如果生产线程需要在队列的两端插入,而消费线程需要从队列的两端删除,也可以只使用BlockingDeque双端队列
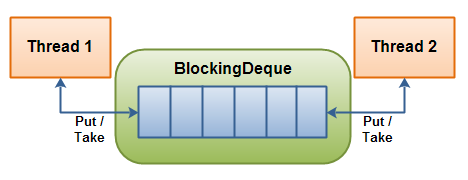
一个线程生产元素并将它们插入到队列两端中的任何一端。如果BlockingDeque当前是满的,插入线程将被阻塞,直到移除线程从BlockingDeque中取出一个元素。如果BlockingDeque当前为空,那么移除线程将被阻塞,直到插入线程将一个元素插入到BlockingDeque中。
1 | public interface BlockingDeque<E> extends BlockingQueue<E>, Deque<E> |
BlockingDeque 方法
BlockingDeque有4组不同的方法,用于插入、删除和检查deque中的元素。每组方法在所要求的操作不能被立即执行的情况下表现也有所不同。参考下面的表格
| 队首操作 | 抛出异常 | 返回特定值 | 阻塞后一直等待 | 阻塞后等待超时 |
|---|---|---|---|---|
| 插入对象 | addFirst(o) | offerFirst(o) | putFirst(o) | offerFirst(o, timeout, timeunit) |
| 移除对象 | removeFirst(o) | pollFirst() | takeFirst() | pollFirst(timeout, timeunit) |
| 检查对象存在 | getFirst() | peekFirst() |
| 队尾操作 | 抛出异常 | 返回特定值 | 阻塞后一直等待 | 阻塞后等待超时 |
|---|---|---|---|---|
| 插入对象 | addLast(o) | offerLast(o) | putLast(o) | offerLast(o, timeout, timeunit) |
| 移除对象 | removeLast(o) | pollLast() | takeLast() | pollLast(timeout, timeunit) |
| 检查对象存在 | getLast() | peekLast() |
这些方法和和BlockingQueue的方法有些相似,只是在方法的基础上加了xxxFirst和xxxLast,所以可以参考我之前的文章对比学习),上面的方法的四种行为分别的含义是
- 抛出异常: 如果调用方法后不能立即响应结果(空队列或满队列),则抛出异常。
- 返回特定值: 如果调用方法后不能立即响应结果(空队列或满队列),则返回特定的值(通常是true/false),true表示方法执行成功,否则表示方法执行失败。
- 阻塞后一直等待: 如果调用方法后不能立即响应结果(空队列或满队列),该方法将被阻塞一直处于等待状态。
- 阻塞后等待超时: 如果调用方法后不能立即响应结果(空队列或满队列),该方法将在一定时间范围内被阻塞等待,也就是在超时时间范围内阻塞。当超出超时时间之后,方法线程将不再阻塞,而是返回一个特定的值(通常是true/false),true表示方法执行成功,否则表示方法执行失败。
BlockingDeque继承BlockingQueue
BlockingDeque接口继承了BlockingQueue接口。这意味着你可以将BlockingDeque作为一个FIFO 的单向队BlockingQueue使用。如果你这样做,各种插入方法将把元素添加到deque的末尾,而移除方法将从deque的队首移除元素。BlockingQueue接口的插入和删除方法,就是这样做的。
下面是BlockingQueue的方法在BlockingDeque实现中的作用对照表
| 对比 | BlockingQueue | BlockingDeque |
|---|---|---|
| 插入 | add(e) | addLast(e) |
| offer(e) | offerLast(e) | |
| put(e) | putLast(e) | |
| offer(e, time, unit) | offerLast(e, time, unit) | |
| 取出 | remove() | removeFirst() |
| poll() | pollFirst() | |
| take() | takeFirst() | |
| poll(time, unit) | pollFirst(time, unit) | |
| 检索 | element() | getFirst() |
| peek() | peekFirst() |
BlockingDeque 接口实现类
BlockingDeque是一个接口,所以当我们真正对它进行实例化的时候,需要使用它的接口实现类。在java.util.concurrent包中的LinkedBlockingDeque方法实现了BlockingDeque接口。
1 | //初始化一个LinkedBlockingDeque |
LinkedBlockingDeque
基于 链表 实现的 BlockingDeque
Node
1 | static final class Node<E> { |
链表的节点以内部类 Node 维护,属性包括 元素、前置节点 和 后置节点
属性、构造方法
1 | // 头节点 |
不同于 ArrayBlockingQueue 的是,可以不指定 容量,默认为 Integer.MAX_VALUE
头插入操作
1 | public void addFirst(E e) { |
最终由 linkFirst 实现节点插入,具体的细节可见注释
尾插入操作
跟 头插入操作 同理,略
头获取操作
1 | public E removeFirst() { |
最终由 unlinkFirst 实现节点获取,具体的细节可见注释
尾获取操作
跟 头获取操作 同理,略
检索操作
1 | public E getFirst() { |
头检索 即返回 first.item,同理 尾检索 返回 last.item
BlockingQueue 方法委托
上文提到 BlockingDeque 也是一个 BlockingQueue,也给出了方法的对应关系,那么实现就是简单的方法委托
1 | public boolean add(E e) { |
Stack 方法委托
同理,BlockingDeque 也可以是个 Stack(栈)
1 | public void push(E e) { |
其他方法
LinkedBlockingDeque 还实现了诸如 remove(Object o) size() contains(Object o) addAll(Collection<? extends E> c) 等很多方法,不再一一解读了
总结
本文介绍了 BlockingDeque 接口和基于链表实现的 LinkedBlockingDeque ,同时支持 队列、双端队列 的 可阻塞 操作,十分强大
来源:
https://rumenz.com/rumenbiji/java-concurrent-container.html
https://rumenz.com/rumenbiji/java-blockingqueue.html
https://rumenz.com/rumenbiji/java-blockingqueue.html
https://rumenz.com/rumenbiji/java-blockingqueue-implementation-class.html
https://rumenz.com/rumenbiji/java-blockingqueue-implementation-class2.html
https://www.cnblogs.com/zimug/p/14867749.html
https://blog.csdn.net/weixin_42189048/article/details/108529875