Fork,join
ForkJoinTask和ForkJoinPool
Fork/join
介绍
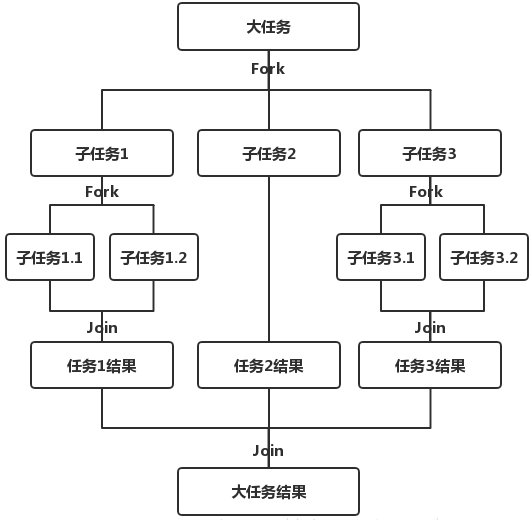
Fork/join框架是java7提供的并行执行任务的框架,是把大任务分割成若干小任务,最后汇总若干小任务的执行结果得到最终的结果。它的思想与MapReduce类似。Fork把一个大任务分割成若干小任务,Join用于合并小任务的结果,最后得到大框架的结果。主要采取工作窃取算法。工作窃取(work-stealing)算法是指某个线程从其它队列窃取任务执行。
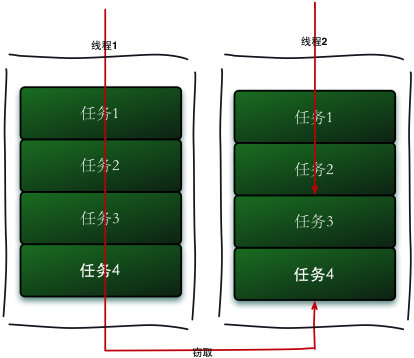
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
对于Fork/Join框架而言,当一个任务正在等待它使用Join操作创建的子任务结束时,执行这个任务的工作线程,寻找其他并未被执行的任务,并开始执行,通过这种方式,线程充分利用它们的运行时间,来提高应用程序的性能。为了实现这个目标,Fork/Join框架执行的任务有一些局限性:
- 任务只能使用Fork、Join操作来作为同步机制,如果使用了其他同步机制,那他们在同步操作时,工作线程则不能执行其他任务。如:在框架的操作中,使任务进入睡眠,那么在这个睡眠期间内,正在执行这个任务的工作线程,将不会执行其他任务
- 所执行的任务,不应该执行IO操作,如读和写数据文件
- 任务不能抛出检查型异常,必须通过必要的代码处理它们
核心是两个类:
ForkJoinTask与ForkJoinPool。Pool主要负责实现,包括上面所介绍的工作窃取算法,管理工作线程和提供关于任务的状态以及它们的执行信息;Task主要提供在任务中,执行Fork与Join操作的机制。
Fork/join代码演示
1 | package com.rumenz.task; |
通过这个例子让我们再来进一步了解ForkJoinTask,任务类继承RecursiveTask,ForkJoinTask与一般的任务的主要区别在于它需要实现compute()方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用fork()方法时,又会进入compute()方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join()方法会等待子任务执行完并得到其结果。
ForkJoinTask和ForkJoinPool
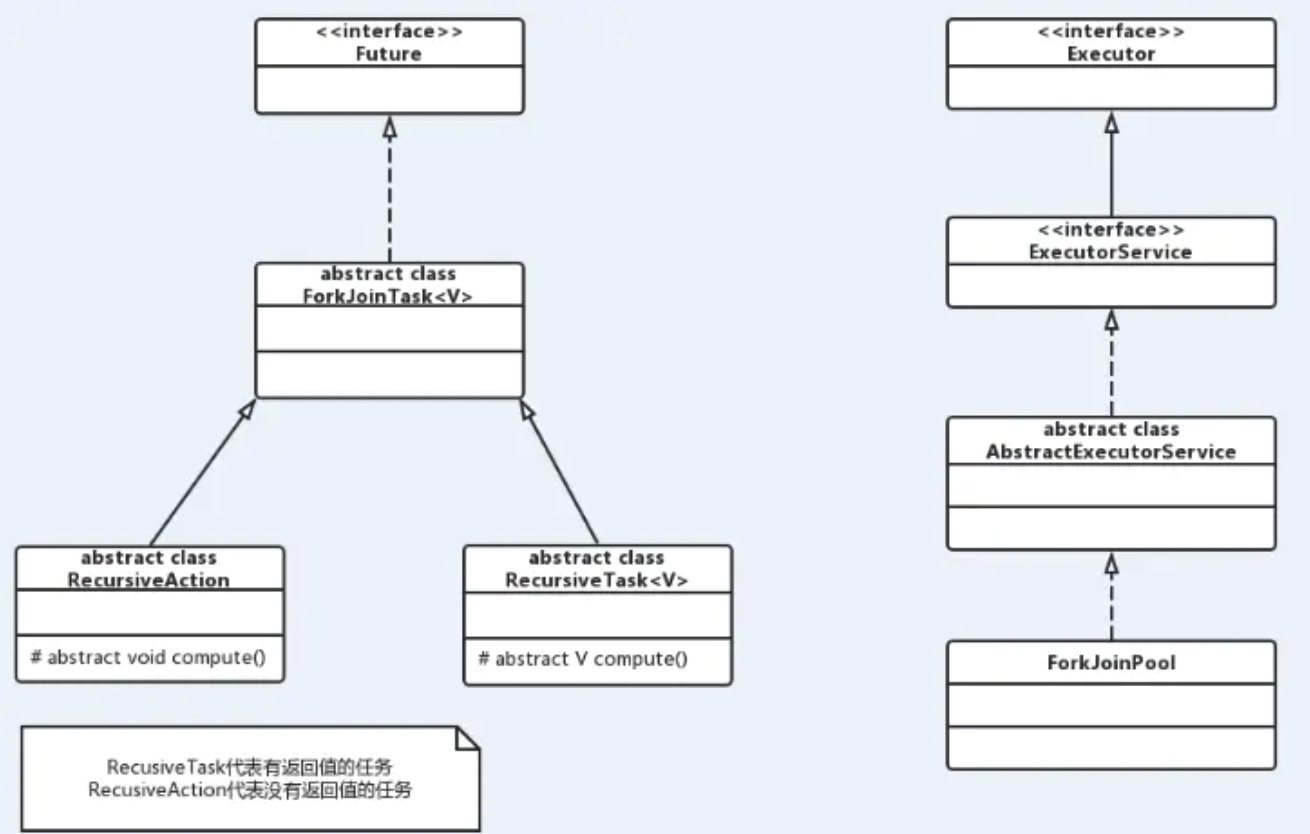
Fork/Join框架中两个核心类ForkJoinTask与ForkJoinPool,声明ForkJoinTask后,将其加入ForkJoinPool中,并返回一个Future对象。
ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行,任务分割的子任务会添加到当前工作维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其它工作线程的队列尾部获取一个任务。ForkJoinTask:我们需要使用ForkJoin框架,首先要创建一个ForkJoin任务。它提供在任务中执行Fork()和Join()操作的机制,通常情况下不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供以下两个子类。RecursiveAction:用于没有返回值的任务。RecursizeTask:用于有返回值的任务。
Exception
ForkJoinTask在执行的时候可能会抛出异常,但是我们没有办法直接在主线程里捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法捕获异常。
1 | public abstract class ForkJoinTask<V> implements Future<V>, Serializable { |
ForkJoinPool源码
1 | public class ForkJoinPool extends AbstractExecutorService { |
FrokJoinPool work stealing算法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
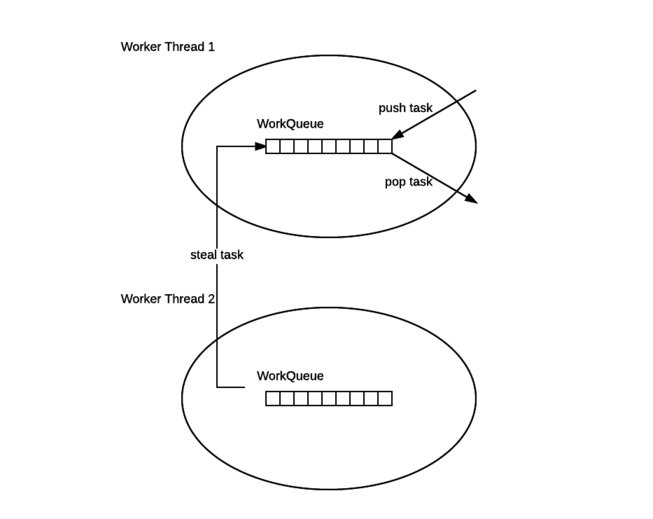
>WorkQueue`是一个双端队列`Deque(Double Ended Queue)`,`Deque`是一种具有队列和栈性质的数据结构,双端队列中的元素可以从两端弹出,其限定插入和删除操作在表的两端进行。
>每个工作线程在运行中产生新的任务(通常因为调用了`fork()`)时,会放在工作队列的对尾,并且工作线程在处理自己的工作队列时,使用的是`LIFO`,也就是说每次从队列尾部取任务来执行。
>每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其它工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
>在遇到`Join()`时,如果需要`Join`的任务尚未完成,则会优先处理其它任务,并等待其完成。
>在没有自己的任务时,也没有任何可以窃取时,则进入休眠。
```java
public class ForkJoinPool extends AbstractExecutorService {
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) {}
public <T> ForkJoinTask<T> submit(Callable<T> task) {}
public <T> ForkJoinTask<T> submit(Runnable task, T result) {}
public ForkJoinTask<?> submit(Runnable task) {}
}
ForkJoinPool自身也拥有工作队列,这些工作队列的作用是用来接收由外部线程(非ForkJoinThread线程)提交过来的任务,而这些工作队列被称为submitting queue。
ForkJoinTask
1 | public abstract class ForkJoinTask<V> implements Future<V>, Serializable { |
fork()做的工作只有一件事,就是把当前任务推入当前线程的工作队列里。
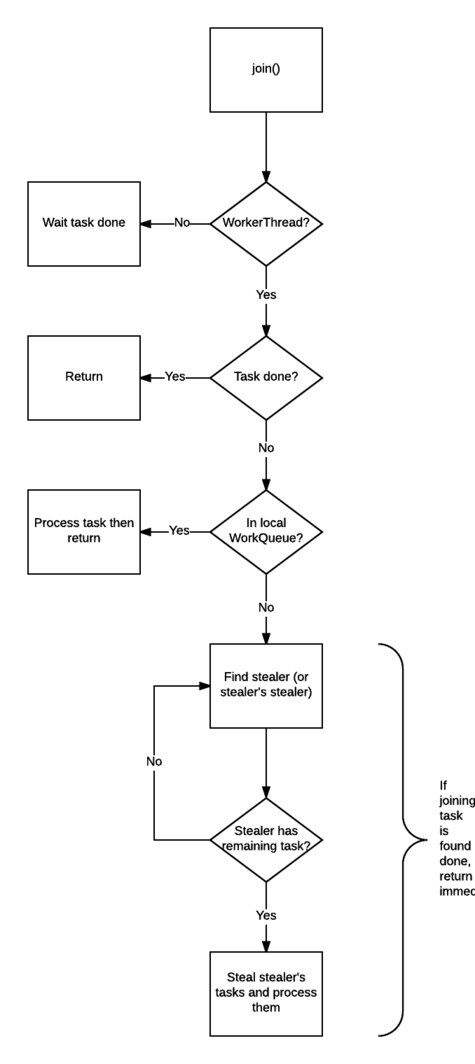
join()的工作就比较复杂,也是join()可以使线程免于被阻塞的原因。
- 检查调用
join()的线程是否是ForkJoinThread线程。如果不是(例如main线程),则阻塞当前线程,等待任务完成。如果是,则不阻塞。 - 检查任务的完成状态,如果已经完成,则直接返回结果。
- 如果任务尚未完成,但是处理自己的工作队列,则完成它。
- 如果任务已经被其它线程偷走,则这个小偷工作队列的任务以先进先出的方式执行,帮助小偷线程尽快完成
join - 如果偷走任务的小偷也已经把自己的任务全部做完,正在等待需要
join的任务时,则找到小偷的小偷(递归执行),帮助它完成它的任务。
ForkJoinPool.submit方法
1 | public static void main(String[] args) throws ExecutionException, InterruptedException { |
每个工作线程自己拥有的工作队列以外,
ForkJoinPool自身也拥有工作队列,这些工作队列的作用是用来接收有外部线程(非ForkJoinPool)提交过来的任务,而这些工作队列被称为submitting queue。
submit()和fork()没有本质区别,只是提交对象变成了submitting queue(还有一些初始化,同步操作)。submitting queue和其它work queue一样,是工作线程窃取的对象,因此当其中的任务被一个工作线程成功窃取时,也就意味着提交的任务真正开始进入执行阶段。
来源
https://rumenz.com/rumenbiji/java-juc-fork-join.html
https://rumenz.com/rumenbiji/java-forkjointask-forkjoinpool.html