Java面试题
- Specification
- Java
- Spring
- MQ
- Cache
- Database
- ES
- Network
- Tools
- Theory
编程思想
设计模式有哪些原则
- 单一职责原则
- 接口隔离原则
- 依赖倒转(倒置)原则
- 里氏替换原则
- 开闭原则(OCP)
- 迪米特法则
- 合成复用原则
设计模式理解
- 对软件设计的解决方案
- 提高拓展性
- 通过模式名称快速沟通相关问题
什么是设计模式中的回调模式
- 可以看作简化版的观察者模式,在方法某个阶段执行完毕时,观察者模式有多个主题和多个可调用方法,回调模式只有一个主题和一个callBack调用方法
饿汉式和懒汉式的区别
饿汉式
初始化时即加载,不会有线程安全问题,但会启动时就占用资源
懒汉式
使用时才加载,需双重锁才解决线程安全问题,节约资源
Spring框架的状态
Spring框架下,如果没有加@Lazy注解,又使用了@Component注解希望被Spring管理Bean,即使是双锁检查懒汉式,也其实在Spring加载时就被调用了getInstance()方法,无法实现资源懒加载。
同时意味着,即使使用基本懒汉单例模式,只要被Spring管理,它就是线程安全的。
编程规范理解
- 利于共同开发
- 降低Bug与维护成本
- 利于Code Review
算法相关
大顶堆小顶堆怎么删除跟节点
TODO
字典树序列化问题
TODO
IPv4转数字,只能用int类型
IPv4地址是由四个8位二进制数组成,可以将它们转换成一个32位的无符号整数来表示。IPv4地址的每个分量都可以用8位二进制数表示,这个二进制数转换为10进制整数即为IPv4地址分量的值。可以将每个分量的值左移位运算8、16、24位后相加,得到一个32位整数表示IPv4地址。
1
2
3
4
5
6
7public void ipv4ToIntTest() {
String ipAddr = "192.168.50.236";
String[] ip = ipAddr.split("\\.");
int result = (Integer.parseInt(ip[0]) << 24) | (Integer.parseInt(ip[1]) << 16) |
(Integer.parseInt(ip[2]) << 8) | Integer.parseInt(ip[3]);
log.info("result: {}", result);
}
如何快速判断一个数是奇数还是偶数,除开对2取余
位运算
1
2
3
4
5if((num & 1) == 0){
//even
}else{
//odd
}
快速排序和优先级队列处理数据复杂度比较
TODO
多线程按顺序输出ABC若干次
TODO
一亿个数中找到最大数
TODO
一个数组每K个一行,存到一个二维数组中,不满补零
TODO
快速排序思路
TODO
一个数组,求最大和,要求组成最大和的元素不是连续的,至少间隔一个元素
TODO
任意字符串去除’ ‘返回字符串中’ ‘的个数和去除’ ‘的字符串,函数可以重载,时间复杂度为O (n)
递归的方式、循环的方式实现了
TODO
2D接雨水
TODO
合并多个有序数组
TODO
深度为5的满二叉树中叶子结点的个数
TODO
数据结构
什么是红黑树?和其他树有什么区别?
什么是红黑树
自平衡二叉查找说,在插入或删除时自动调整树结构,保持树的平衡状态,从而保证树的高度较低,提高查找、插入和删除的效率
和其他树有什么区别
主要是其自平衡特性
BST
红黑树属于它,但它不一定是红黑树,它不能自平衡,因此可能高度O(n),时间复杂度也是O(n)
AVL
也是一种自平衡树,但AVL要求左右子树高度差不能超过1,因此插入和删除时需要更多旋转操作,实现更复杂,查找效率更高,但插入/删除效率更低。
B-Tree/B+Tree
多路查找树,查询效率更高,但实现更复杂
堆结构与树结构的区别
TODO
搜索二叉树怎么遍历
TODO
左小右大
CPU L1 L2 L3哪些共享
TODO
HashMap 的红黑树、红黑树上的红节点主要是干什么的
红黑树中的红色节点用作平衡机制以确保树保持平衡。红黑树是一种自平衡二叉搜索树,这意味着它们会自动调整其结构以保持对数高度和高效的搜索和插入操作。
在红黑树中,每个节点要么是红色的,要么是黑色的。根节点和所有叶节点(即树底部的空节点)始终为黑色。红色节点可以有黑色或红色孩子,但黑色节点只能有黑色孩子。这种安排确保从根节点到任何叶节点的最长路径不超过最短路径的两倍。
当一个节点被插入到红黑树中时,它最初是红色的。然后调整树以保持红黑属性,其中包括:
- 每个节点要么是红色要么是黑色。
- 根节点始终为黑色。
- 如果一个节点是红色的,那么它的两个孩子都必须是黑色的。
- 从节点到其后代空节点的每条路径都包含相同数量的黑色节点。
为了保持这些属性,树可能需要执行节点的旋转和重新着色。红色节点在此过程中起着至关重要的作用,因为它们允许树执行旋转以保持树的平衡,同时避免过高。
总之,红黑树中的红色节点充当平衡机制,以确保树保持平衡并保持其高效的搜索和插入操作。
十几亿个数据,实现黑白名单,标出黑名单的几个人
Bloom过滤器
优势
空间效率:布隆过滤器使用紧凑的位数组来表示集合,这意味着它们比散列表等传统数据结构需要更少的内存。
快速成员资格测试:布隆过滤器可以通过执行一些简单的按位运算快速检查元素是否是集合的成员。
可扩展性:布隆过滤器可以扩展到非常大的数据集,使其适用于拥有超过 10 亿数据的用例。
低漏报率:Bloom 过滤器返回漏报率的可能性很低(即表明某个元素实际上不在集合中)。缺陷
误报:Bloom 过滤器可以返回误报(即,表明一个元素在集合中,而实际上它不在集合中),尽管这种情况发生的概率可以通过调整过滤器的参数来控制。
单向:布隆过滤器是一种单向数据结构,这意味着一旦添加了元素,您就无法从过滤器中检索原始元素。
有限的功能:布隆过滤器只能测试成员资格,不能执行删除或交集等操作。
总而言之,如果您需要一种节省空间、可扩展且快速的方式来实现包含超过 10 亿条数据的黑白名单并在黑名单中标记少数人,布隆过滤器可能是一个不错的选择。但是,您还应该考虑在特定用例中使用布隆过滤器的限制和权衡。
计算机内存管理
内存的物理结构
内存由许多个存储单元组成,每个存储单元都有一个唯一的地址,通过地址来访问内存中的数据。
内存的逻辑结构
内存被操作系统分成多个逻辑块,如页、段或区域等,操作系统可以对这些逻辑块进行分配、回收和管理。
内存的分配
在运行程序时,操作系统需要为程序分配内存空间,内存分配可以采用静态分配或动态分配。静态分配指在程序编译时就已经确定了程序需要的内存空间大小,动态分配则是在程序运行时根据实际需要来动态地分配内存空间。
内存的回收
在程序运行结束后,操作系统需要回收程序使用的内存空间,以便让其他程序可以使用这些内存空间。
内存的保护
为了保护操作系统和其他程序的正常运行,操作系统需要对内存进行保护,以防止程序越界访问、恶意代码修改内存等安全问题。
内存的共享
在多个进程间共享内存可以提高系统的性能和效率,但同时也带来了一些安全和同步问题,操作系统需要对内存共享进行管理和控制。
上下文无关文法和正则文法的区别
正则定义与上下文无关文法的重要区别在于,在正则定义中是不允许递归定义的,例如A → aA|b不是一个正则定义,为其左边的A必须是一个新的符号,也就是说不能在其他地方定义过,但是其右边要求每一个符号都是定义过的,因此这个定义无法满足。而上下文无关文法则没有这个约束,因此A → aA|b是一个上下文无关文法的产生式,但不是正则定义的定义式。
正则表达式在编译器构建中一般用来进行词法分析,通过NFA、DFA就可以识别,而更复杂的文法就需要以来其他算法了。
定义一个数据结构,包含insert和queryMedium两个方法,查询高频操作,插入低频操作,要求查询效率最优
TODO
Java 相关
基础
Java基本数据类型
- long short int double float char byte boolean
float如何判断是否为0
- IEEE754 ,0.00000f<1e-6
对象创建到销毁的流程
TODO
abstract应用范围
TODO
interface默认修饰符
- public abstract
构造方法
TODO
super this怎么用
TODO
switch如何实现
比较
- 字符串使用hash && equals 比较
- 枚举类使用ordinal方法转int比较
字节码产生一条goto语句
注意,Java虚拟机特性使switch不支持long类型
Java包装类型理解
- 对于基本类型的包装
- 存储位置不同
- 包装类型存储于堆,通过地址引用
- 基本类型根据不同方法存放不同位置
- 方法-栈帧局部变量表
- 类成员变量-栈
- 静态变量/常量-方法区
- 包装类默认值为Null值,基本类型不能为null
- OOP思想
Java面向对象特征
- 封装,继承,多态
值类型和引用类型分别在JVM哪个区域
值类型
栈
引用类型
堆
String是值类型吗
否,引用类型
每当创建一个字符串时,如果该字符串的值已经存在于字符串常量池中,那么将返回常量池中的这个字符串对象的引用,否则将会在常量池中新建一个字符串并返回这个字符串对象的引用
接口能不能实现接口
- 不能,只能继承
抽象类和接口的区别,类可以继承多个类么,接口可以继承多个接口么,类可以实现多个接口么?
抽象类和接口的区别
- 一个类只能继承一个抽象类(单继承),却能实现多接口(多实现)
- 抽象类可以有定义和实现,接口原本只有定义,JDK1.8后可以default实现
- 接口强调特定功能实现,抽象类强调所属关系
- 接口成员变量默认public static final,必须赋值且不能修改,所有成员方法都是public、abstract的。抽象类变量默认default,可在自类被重新定义,也可以被重新赋值。
类可以继承多个类么
不可以
接口可以继承多个接口么
可以
类可以实现多个接口么
可以
父类静态方法能否被子类重写
- 不能,只能继承,不能重写
静态属性和静态方法是否可以被继承
- 可以,且可以覆盖,如果想用父类的属性和变量,则需使用父类
为什么重写Equals一定也要重写HashCode
- 自定义对象要比较时,先比较hashCode再比较equals,hashCode保证性能,equals保证可靠性
- 从Object继承的这两个方法都是
比较内存地址,如果不重写HashCode,自定义的两个对象内存地址肯定不一样导致比较失效,Equals比较同理,Object比较也是内存地址,也会导致比较失效。 - https://zhuanlan.zhihu.com/p/61307537
- https://segmentfault.com/a/1190000024478811
HashCode相同,是否Equals,反之是否相同
否
两个对象equals,hashcode一定相同,因此比较时会先比较hashCode,如果不同则直接返回false
hashcode相同,不一定equles
对一个数异或两次等于没有异或
异或是一种按位逻辑韵味,规则为:两个二进制位相同则结果为0,不同则为1
异或满足交换律和结合律,因此对一个数异或异或两次没有异或
1
2
3x = x ^ y // (a ^ b, b)
y = x ^ y // (a ^ b, a ^ b ^ b) => (a ^ b, a)
x = x ^ y // (a ^ b ^ a, a) => (b, a)
float在内存中怎么表示
- s | eeeeeeee | mmm mmmm mmmm mmmm mmmm mmmm
- 符号位:31位,符号0为负,1为正
- 指数位:23-30位,用8位存储指数部分
- 尾数位:0-22位,存储小数部分
数组动态分配内存如何实现
- Java中动态数组分配内存是通过JVM中的Heap实现的。
- Java数组是一种固定长度的数据结构,因此分配动态数组的实现方式是创建一个新的更大的数组,将原数组数据复制System.arraycopy(),并释放原数组空间。
- 频繁操作会导致性能问题,应尽量避免数组扩容
如何防止非原子操作的冲突问题
- 使用synchronized关键字,避免并发到这数据冲突
- 使用ReentrantLock
- 使用Atomic包
- 使用ThreadLocal
- 使用JUC并发容器
什么是哈夫曼树
- 最优二叉树,是一种带权路径长度最短的树,常用于数据压缩中的编码和解码
- 每个叶子节点对应着一个权值,而每个非叶子节点对应着一个权值之和。哈夫曼编码则是将字符映射为哈夫曼树中对应的叶子节点的路径,路径的方向为从根节点到叶子节点的方向。由于哈夫曼树的带权路径长度最短,所以哈夫曼编码也是一种最优编码方式,能够实现高效的数据压缩。
Object 常用方法及每个方法的大致含义
Object.equals()
判断对象hashCode是否相同
Object.wait()
线程停止
Object.toString()
将对象转换为字符串
在JDK1.5中引入了泛型,泛型的存在是用来解决什么问题
- 泛型主要针对向下转型时所带来的安全隐患,其核心组成是在声明类或接口时,不设置参数或属性的类型
- 第一是泛化。可以用T代表任意类型Java语言中引入泛型是一个较大的功能增强不仅语言、类型系统和编译器有了较大的变化,以支持泛型,而且类库也进行了大翻修,所以许多重要的类,比如集合框架,都已经成为泛型化的了,这带来了很多好处。
- 第二是类型安全。泛型的一个主要目标就是提高ava程序的类型安全,使用泛型可以使编译器知道变量的类型限制,进而可以在更高程度上验证类型假设。如果不用泛型,则必须使用强制类型转换,而强制类型转换不安全,在运行期可能发生ClassCast Exception异常,如果使用泛型,则会在编译期就能发现该错误。第三是消除强制类型转换。泛型可以消除源代码中的许多强制类型转换,这样可以使代码更加可读,并减少出错
- 的机会。
- 第四是向后兼容。支持泛型的Java编译器(例如JDK1.5中的Javac)可以用来编译经过泛型扩充的Java程序(Generics Java程序),但是现有的没有使用泛型扩充的Java程序仍然可以用这些编译器来编译。
- JAVA 泛型只存在于编译时期,在运行时期会被擦除
泛型中extends和super的区别
- extends 表示包括T在内的任何T的子类
- super 表示包括T在哪的任何T的父类
有没有可能2个不相等的对象有相同的hashcode
有,Hash冲突
拉链法:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被 分配到同一个索引上的多个节点可以用这个单向链表进行存储.
开放定址法:一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找 到,并将记录存入
再哈希:又叫双哈希法,有多个不同的Hash函数.当发生冲突时,使用第二个,第三个….等哈希函数计算 地址,直到无冲突.
举例几个树形结构
- B+Tree,MySQL
- 红黑树,HashMap
Java异常类体系共同祖先
Throwable
内部包含Error和Exception
Error和Exception的区别
- Error 一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等。仅靠程序本身无法恢复
- Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Java异常框架有哪些
原生
Exception、RuntimeException、NullPointerException、IOException等Spring框架
Spring自定义的异常类、Spring AOP中的异常处理、Spring MVC中的异常处理等。
Log4j2
提供了
ThrowableProxy用于封装异常信息,包括堆栈跟踪、异常类型、异常信息等
你知道什么是指令重排序?为什么要重排序?
- 指令重排序是指源码顺序和程序顺序不一样,或者说程序顺序和执行的顺序不一致,重排序的对象是指令。 指令重排序是编译器处于性能考虑,在不影响程序(单线程程序) 指令重排序不是必然发生的,指令重排序会导致线程安全问题。
- volatile(引申Singleton Pattern为什么使用)
Java中的volatile关键是什么作用?在Java中它跟synchronized方法有什么不同
Java中的volatile关键是什么作用
多线程环境下,保证共享变量的可见性,当一个线程修改共享变量的值,其他线程可以立即看到,其他线程回去主内存重新读取该变量的值,避免数据不一致问题。
禁止指令重排序,保证多线程环境下,共享变量的读写是有序的
在Java中它跟synchronized方法有什么不同
volatile可以保证可见性和有序性,不能保证原子性。
synchronized可以保证可见效,有序性和原子性
Overload、Override、Overwrite的区别
- overload意为重载,同一个类中,存在多个方法名相同的函数,但是他们拥有不同的参数
- override意为覆盖,针对父类,实现类而言,参数名称相同,方法不同
- overwrite意为重写,Java没有
什么是浅拷贝和深拷贝
- 浅拷贝只是增加了一个指针指向已经存在的内存
- 深拷贝就是增加一个指针并且申请一个新的内存,使这个增加的指针指向这个新的内存,采用深拷贝的情况下,释放内存的时候就不会出现在浅拷贝时重复释放同一内存的错误。
- 浅拷贝更改数据会变更原数据
什么是不可变对象,它对写并发应用有什么帮助
- 一旦创建及无法被修改的对象称为不可变对象。
- 并发应用的帮助
- 多线程下不会出现线程同步问题,不需要担心数据被其他线程修改
- 可以作为Map的Key 和Set元素
- 但由于不可变,因此每次创建一个不同的对象都会产生一个新对象
如何创建不可变的类?
- private + final修饰
- 不暴露改变成员变量的方法,如setter
- 通过构造器初始化所有成员,进行深拷贝(this.myArray = array.clone())
- getter方法中,不要返回对象本身,而是返回clone对象
String能不能有子类,为什么 String 被设计为是不可变的?
String能不能有子类
不能,public final class String
JDK 1.8 本质是final char value[],JDK 1.9 本质是 final byte[] value;
实际可以通过反射变更array
为什么 String 被设计为是不可变的
线程安全,不可变对象一定是线程安全的
字符串常量池,节约空间
Hash Code 唯一性,JVM直接缓存HashCode,对于HashMap类引用查找速度快
String转Integer的方式和原理
方式
Integer.parseInt();
Integer.valueOf();
原理
先判断是否有符号,再循环字符,Character.digit(char ch, int radix)转换
描述动态代理的几种实现方式,分别说出相应的优缺点
- JDKProxy
- JDK自带
- 只能代理接口
- 保持原类存在下,生成一个继承Proxy.class的新类
- CGLibProxy
- 第三方类,通过继承的方法进行代理
- 可以代理类和方法,不能代理final类和final方法
- 直接生成Proxy代理类,字节码方式替换原始类
- Spring-AOP | swzxsyh
JAVA实现反射的两种方式?为什么要这样设计?
Class.forName(); Object.getClass();1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
- 增强程序的灵活性和可扩展性。
#### JAVA的反射机制
- 反射机制
- 在运行时动态获取类的信息,以及动态创建对象、调用方法、访问熟悉。
反射机制允许运行时获取类的方法、字段、注解等信息,并可以动态操作类的实例,为程序提供灵活性。
- 主要接口
- Class 类:代表一个类的字节码对象,可以获取类的名称、修饰符、构造方法、方法、字段、注解等信息。
- Constructor 类:代表一个类的构造方法,可以通过 Constructor 类动态地创建类的实例。
- Method 类:代表一个类的方法,可以通过 Method 类动态地调用类的方法。
- Field 类:代表一个类的字段,可以通过 Field 类动态地访问和修改类的字段值。
- Annotation 接口:代表一个类或方法的注解,可以通过 Annotation 接口获取类或方法的注解信息。
- 应用场景
- 动态代理、框架开发、对象序列化、注解处理、模块化编程等。但是由于反射机制在运行时动态地创建对象和调用方法,因此可能会影响程序的性能,需要在使用时慎重考虑。
#### Java 静态代理和动态代理区别
- Static Proxy 中,代理类是在编译时创建的,并指定了一组固定的接口
Java Static Proxy 涉及创建一个实现与原始对象相同接口的代理类,并且对原始对象的所有方法调用都被转发到代理对象。然后,代理对象可以在调用原始对象的方法之前或之后执行其他操作。静态代理在目标对象是固定的并且在编译时已知的场景中很有用。
- Dynamic Proxy 中,代理类是在运行时创建的,可以添加接口动态地。
Java 动态代理使用内置的 java.lang.reflect.Proxy 类在运行时创建代理实例。动态代理允许更大的灵活性,因为代理实现的接口可以在运行时动态确定。当编译时不知道目标对象或需要代理大量对象时,动态代理很有用。
Static Proxy 和 Dynamic Proxy 的另一个区别是 Static Proxy 可以为接口和具体类创建,而 Dynamic Proxy 只能为接口创建。
总体而言,静态代理和动态代理都用于在不更改对象代码的情况下向对象添加附加功能,两者之间的选择取决于用例的具体要求。
#### CAS原理
- CAS存在3个参数
内存地址V,期望值A,新值B。
- 当多个线程试图修改同一个变量时,只有一个线程能够成功修改,其他线程失败。如果内存地址V的值与期望值A相等,则判断没修改过,替换为B则成功,否则失败。
- CAS算法的实现通常依赖于CPU的底层指令,比如x86架构中的CMPXCHG指令
#### 怎么保证幂等
- 幂等性是指同一个操作无论请求多少次,其结果都相同
- 保证方式
- 唯一性约束:数据库使用唯一性约束保证数据唯一性
- 乐观锁机制: 使用版本号标记,如果版本号错误,则失败
- 请求去重:在前端生成一个唯一key,后端检查是否已接受过该请求
- 幂等性接口设计:如在更新数据时,只更新发生变化的字段
#### 什么是原子操作,Java中的原子操作是什么
- 原子操作
- 不可被中断的一个或一系列操作,要么全部完成,要么全部不完成
- Java原子操作
- Atomic类提供原子方法,保证原子性
#### AtomicInteger set方法是线程安全的吗
- 是线程安全的。Java赋值是原子操作,且同时读写才关注原子性,只写入是原子的
#### 如何同步一个原子操作
- 使用Atomic原子类中的方法
- get(): 获取当前值
- set(value): 设置当前值
- getAndSet(value):获取当前并设置为指定值
- compareAndSet(expect,update): 比较当前值如果是expect则设定为update
- 使用`compareAndSet()`方法可以实现同步一个原子操作的效果
- 将需要同步的原子操作放入一个循环,每次循环尝试使用compareAndSet()方法更新原子变量的值
- compareAndSet() 返回true表示成功,跳出循环
- compareAndSet() 返回false表示失败,当前值已被修改,需重新获取原子变量的最新值再进行操作,进入下一次循环
```java
/**
* CompareAndSet() Test
*/
@Test
public void compareAndSetTest() {
AtomicInteger counter = new AtomicInteger(0);
int i = 0;
while (true) {
int oldValue = counter.get();
int newValue = oldValue++;
if (counter.compareAndSet(oldValue, newValue)) {
break;
}
i++;
System.out.println("current i:" + i);
if (i == 15) {
break;
}
}
}
Servlet生命周期
初始化阶段
当Servlet容器接收到一个Servlet的请求时,它首先会检查是否已经加载了该Servlet的实例。如果没有,则会根据web.xml配置文件中的<servlet>和<servlet-mapping>元素来创建和初始化一个新的Servlet实例。在初始化过程中,容器会调用Servlet的init()方法来初始化Servlet实例,并传递一个ServletConfig对象,该对象包含了Servlet的初始化参数
服务阶段
在Servlet实例初始化完成后,容器会将客户端的请求分派给对应的Servlet实例,并调用该实例的
service()方法来处理请求。在service()方法中,Servlet可以使用一些内置的对象,如ServletRequest和ServletResponse来访问请求和响应的信息,并通过这些对象与客户端进行交互销毁阶段
清理一些资源,如关闭数据库连接、释放文件句柄等等
SimpleWebServer支持HTTPS吗
- 不支持。如果不能替换为Tomcat等Web服务器,可以使用Nginx反向代理
static 和final static的区别
- final static变量不可改,且必须在声明时初始化
- 普通static可以变更,在任何时候初始化
Java内存池提供的接口,实现方式
内存池提供的接口
ByteBuffer allocate(int capacity): 分配一个具有指定容量的新的ByteBuffer实例。ByteBuffer allocateDirect(int capacity): 分配一个具有指定容量的新的直接ByteBuffer实例。ByteBuffer wrap(byte[] array): 包装一个字节数组为ByteBuffer实例。ByteBuffer wrap(byte[] array, int offset, int length): 从指定的偏移量开始,使用指定长度包装一个字节数组为ByteBuffer实例。实现方式
Java内存池的实现方式通常是基于对象池的方式,对象池是一种可以重用已经创建的对象的模式。在Java中,内存池就是一种对象池,它维护了一个对象列表,可以在需要时为请求对象的线程提供对象,并将使用后的对象返回给池。
空闲链表法中每个节点管理的内存大小
- 常用的空闲链表法中,每个节点管理的内存大小可以是一个定值,例如64字节、128字节等等,也可以是一个区间,例如64-128字节、128-256字节等等,具体大小根据不同的应用场景而定。
- 当需要申请内存时,可以根据内存大小在对应的节点上进行申请。在释放内存时,可以将内存块重新加入到对应的节点中,以便后续可以被重复利用
EJB是什么
TODO
Java读取配置文件方法 xml或properties
TODO
反射实例化对象
List && Map 相关
Java集合理解,Map的理解,HashMap关键属性
Java集合
即容器,一个是Collection接口,存放单一元素,另一个是Map接口,存储键值对。
Collection接口下存在Set、List、Queue三大子接口
List
ArrayList:Object[]数组Vector:Object[]数组LinkedList: 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
Set
HashSet(无序,唯一): 基于HashMap实现的,底层采用HashMap来保存元素LinkedHashSet:LinkedHashSet是HashSet的子类,并且其内部是通过LinkedHashMap来实现的。有点类似于我们之前说的LinkedHashMap其内部是基于HashMap实现一样,不过还是有一点点区别的TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)
Queue
PriorityQueue:Object[]数组来实现二叉堆ArrayQueue(Dqueue子接口再实现):Object[]数组 + 双指针
Map
HashMap: JDK1.8 之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间LinkedHashMap:LinkedHashMap继承自HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。Hashtable: 数组+链表组成的,数组是Hashtable的主体,链表则是主要为了解决哈希冲突而存在的TreeMap: 红黑树(自平衡的排序二叉树)
List: 可存储有序重复的元素
Set: 存储无序不可重复元素
Queue: 按特定规则确定顺序,存储的元素有序可重复
Map: 使用K-V存储,Key无序不可重复,Value无序,可重复,每个Key正常情况下最多映射一个值
HashMap关键属性
java.util.HashMap
1
2
3
4
5
6
7
8
9
10
11
12
13// 存放临界值的数组
transient Node<K,V>[] table;
//存放数组个数
transient int size;
//被修改的次数
transient int modCount;
//临界值,当大小超过时,会进行扩容
int threshold;
//加载因子,如果增大,空间利用率提高,但是碰撞概率也加大,链表长度增常,降低查找效率
final float loadFactor;
用过哪些Map类,都有什么区别,HashMap是线程安全的吗
- 用过哪些Map类
- ConcurrentHashMap线程安全,K-V 设定为@Nullable。数组+链表+红黑树
- LinkedHashMap记录插入顺序
- TreeMap根据Key排序
- HashMap是线程安全的吗
- 不是,HashMap不支持线程的同步
Array和List区别
- Array大小固定,List动态
- Array只能基本类型,List只能保存对象
- List有多种实现,提供添加、删除等方法
ArrayList扩容机制
TODO
为什么ArrayList比LinkedList高效
- ArrayList底层是数组,LinkedList底层基于链表。由于数组在内存中是连续的,因此访问元素时间复杂度是O(1),链表需要遍历,时间复杂度是O(n)
HashMap比TreeMap更高效吗
- HashMap底层是Hash表,TreeMap底层是红黑树。
- Hash表查找元素时间复杂度是O(1),红黑树是O(n log n),因此少量数据查找方面HashMap更高效
- 如果是大量数据,当HashMap元素大于MIN_TREEIFY_CAPACITY (默认为64) ,bucket元素达到TREEIFY_THRESHOLD (默认为8) 时,会转换为红黑树。此时TreeMap效率会更高
数组链表谁更高效
- 取决于场景和操作类型,插入删除链表更高效,遍历元素数组更高效
如何高效Copy数组
- System.copyArray();
- Arrays.copyOf();
HashMap初始化容量1W,存1W个是否会扩容
当数值为1W时,不会扩容,但如果是1000,则会进行扩容
HashMap会调用tableSizeFor方法进行运算,运算 result * 0.75 是初始化的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32/**
* 当前方法存在命名不规范问题
*
* @throws NoSuchMethodException
* @throws InvocationTargetException
* @throws IllegalAccessException
*/
public void tableSizeFor() throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
final double loadFactor = 0.75;
final int cap_1K = 1000;
final int cap_1W = 10000;
Method tableSizeFor = HashMap.class.getDeclaredMethod("tableSizeFor", int.class);
tableSizeFor.setAccessible(Boolean.TRUE);
int result_1K = (int) tableSizeFor.invoke(null, cap_1K);
int result_1W = (int) tableSizeFor.invoke(null, cap_1W);
System.out.println("tableSizeFor 1000 result: " + result_1K);
System.out.println("tableSizeFor 10000 result: " + result_1W + "\n");
int finalSize_1K = (int) (result_1K * loadFactor);
int finalSize_1W = (int) (result_1W * loadFactor);
System.out.println("finalSize 1000 result: " + finalSize_1K);
System.out.println("finalSize 10000 result: " + finalSize_1W);
}
//tableSizeFor 1000 result: 1024
//tableSizeFor 10000 result: 16384
//finalSize 1000 result: 768
//finalSize 10000 result: 12288
解决Hash冲突的办法有哪些?HashMap用的哪种?
- 解决Hash冲突的办法有哪些
- 开放地址法:被占用就找下一个位置。下一个位置的方案有 线性探测再散列,平方探测再散列,随机探测再散列
- 线性探测再散列:发生冲突时,顺序查看哈希表下一单元是否可用,直到找到可用的单元
- 二次探测再散列:发生冲突时,以冲突的位置为中心向左右探测是否有可用单元
- 伪随机探测再散列:通过一组伪随机数列计算得到对应的单位位置
- 链地址法:Hash相同的放在一个新的同义词链的链表里,链头指针放到Value位置
- 再散列:运用多个Hash函数,冲突时使用其他函数运算值
- 建立公共溢出区:将Hash表分为基本表和溢出表,发生冲突的全放入溢出表
- 开放地址法:被占用就找下一个位置。下一个位置的方案有 线性探测再散列,平方探测再散列,随机探测再散列
- HashMap用的哪种
- 链地址法
HashMap如何通过K-V管理数据
- HashMap是一种机遇哈希表实现Map接口的数据结构,由数组+链表/红黑树组成的。HashMap美国元素成为Entry,由Key-Value组成
- 底层是数组,美国元素是一个链表。当添加一个元素时,先根据Key的HashCode计算出该元素在Array中Bucket的位置,如果没有将元素放入Bucket,如果有,则遍历Bucket中的LinkedList,如果遍历有相同Key则替换Value,如果没有则将元素添加到Linked List 末尾
HashMap为什么选择2的倍数当作容量
扩容时位运算效率高
key.hashCode() & (length-1)碰撞概率降低
HashMap初始为什么16
- JDK 没有给出理由,可能是位运算方便,且16更通用于业务
HashMap因子为什么是0.75
可能与泊松分布相关。过小占有空间大,过大容易增加碰撞概率,0.75属于经验中间值,提高利用率且降低冲突。
HashMap扩容后如何再散列(rehash)
- 创建新数组,大小为原来数组大小的2倍
- 遍历数组中每一个元素,重新hash并放入新数组对应的位置中
- 如果出现hash冲突,则使用链表或红黑树等数据结构解决
- 当所有元素rehash完成后,使用新数组体会旧数组
- 该操作期间需要保证线程安全!
HashMap在Java 7 为什么会进入死循环
JDK 1.7 使用头插法(bucket index = hash & (n-1),头插法+链表+多线程+HashMap扩容可能导致死循环
问题主要出在头插法时,新元素是插入链表头部的,某些情况下会导致链表倒置,从而导致链表长度变长,进而影响遍历时间,最坏情况下无法遍历到数据,造成死循环
具体而言:头插入新元素时,遇到相同Key,新节点会放到链表头部,原来的节点成为新节点next指针,这样就会出现链表倒置。这种倒置是循序渐进的,一个节点的next指针会指向下一个节点的next指针,这样会倒置整个链表顺序被倒置。
这部分内容与多线程有密切关联。
插入相同Key节点时,Thread-A执行,将节点插入链表头部,链表变为{A-B-C},此时Thread-B也执行,它看到的仍然是{A-B-C},插入新节点后变成{B’-A-B-C},其中B’ 是Thread-B新插入的节点,如果另一个线程执行查询操作,从头部查询,发现链表中存在两个相同的Key,导致查询错误。
Java 8 使用尾插法解决该问题,但如果Hash冲突过多,仍会导致链表过长,影响查询效率,因此需尽量避免hash冲突
HashMap为什么要在存储量变更时切换结构,如何切换
- 当元素超过阈值时(容量*0.75),需要进行扩容操作
- 扩容会进行rehash操作,这个过程需要保证线程安全。这个扩容可能发生哈希冲突
- 避免每次判断这个位置是链表还是红黑树,当Hash冲突达到8时,HashMap会将链表转换为红黑树。当红黑树元素小于6时,会退化成链表。
HashMap为什么查询时间复杂度为O(1)
TODO
ConcurrentHashMap如何解决安全问题
JDK 7中,使用分段锁,多线程可以在每个分段操作避免冲突。如果在同一个Segment操作,则由当前Segment提供互斥锁保证线程安全(内部使用volatile、synchronized,CAS机制保障)。遍历数据基于快照查询,保证不会抛出ConcurrentModificationException异常。
JDK 8中,使用CAS操作的无锁并发控制,相比于分段锁,减少锁竞争,提高性能。同样基于分段,但是使用的是基于 CAS 和 Synchronized 的新机制,即使用了一种名为
synchronized-with-capacity的策略。线程数量不多时使用CAS,当线程超过某个阈值时转换为synchronized,此时比CAS效率更高。
与JDK7分段锁的区别,降低了锁的颗粒度,将锁整个Map,变更锁Segment对象,减少锁竞争与锁开销,提高并发性能。
ConcurrentHashMap在Java 7性能问题
- 分段锁锁整个Map,增加开销降低并发性能
ConcurrentHashMap为什么在Java 8放弃了分段锁
- 为了提升性能
什么是阻塞队列?你知道Java中有哪些阻塞队列吗?
- 什么是阻塞队列
- 是一种特殊的数据结构,在队列已满或空的情况下,会暂停插入/获取操作,直到满足插入/获取条件为止,从而有效协调多线程之间的数据交换
- 阻塞队列举例
- ArrayBlockingQueue:数组有界队列,FIFO
- LinkedBlockingQueue:链表有界队列,FIFO。如果列表为空,获取操作会进入阻塞状态
- PriorityBlockingQueue:支持优先级排序的无界队列,元素按照自然排序或指定排序,为空时获取操作进入阻塞状态
- SynchronousQueue:不存储元素的队列,用于线程之间之间传输,每个插入操作必须等待另一个线程的删除操作,否则插入会一直堵塞。同理,每个删除也必须等待一个插入动作。
- DelayQueue: 支持延迟获取元素的无界阻塞队列,元素只有到期才能获取。排序可以FIFO也可以自定义
ArrayBlockingQueue原理
- 实现BlockingQueue接口,容量需指定,且不可变
- 内部使用一个长数组作为队列的存储结构,队列的头尾分别对应数组的头尾,队列满时抛异常,空时阻塞。
- 基于经典的”Pub-Sub”模型
- 内部维护了一个ReentrantLock和2个Condition,分别用于控制生产者线程和消费者线程的等待和唤醒。当队列已满时,生产者线程调用 put() 方法时会被阻塞,直到有其他线程从队列中取出一个元素并调用了 signal() 方法唤醒生产者线程;当队列为空时,消费者线程调用 take() 方法时会被阻塞,直到有其他线程向队列中插入了一个元素并调用了 signal() 方法唤醒消费者线程
用Java写代码来解决生产者——消费者问题
private static ExecutorService executorService = new ThreadPoolExecutor(5, 10, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>(5 * 2), new ThreadPoolExecutor.CallerRunsPolicy()); // 缓冲区大小 final int capacity = 5; // 缓冲区 LinkedList<Integer> buffer = new LinkedList<>(); public static void main(String[] args) { //生产者线程 executorService.execute(()->new ProducerConsumerExampleTest().publish()); // 消费者线程 executorService.execute(()->new ProducerConsumerExampleTest().subscribe()); } private void publish() { int value = 0; while (true) { synchronized (buffer) { while (buffer.size() == capacity) { try { buffer.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } //生产数据并加入缓冲区 buffer.add(value++); log.info("生产者生产了:{}", value); //通知消费者消费 buffer.notifyAll(); } } } private void subscribe() { while (true) { synchronized (buffer) { while (buffer.isEmpty()) { try { buffer.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } // 从缓冲区中取出数据并消费 int value = buffer.remove(); log.info("生产者消费了:{}", value); //通知生产者生产 buffer.notifyAll(); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
### Thread && Lock 相关
#### 进程和线程的区别,使用线程真的能节省时间吗
- 进程间数据独立,线程数据共享,一个进程可以包括多个线程
- 不一定,要看设置是否合理,CPU分页调度问题
#### 线程实现方式
- 继承Thread
- 实现Runnable/Callable
#### 线程有几种状态
- 在JAVA中有六种状态
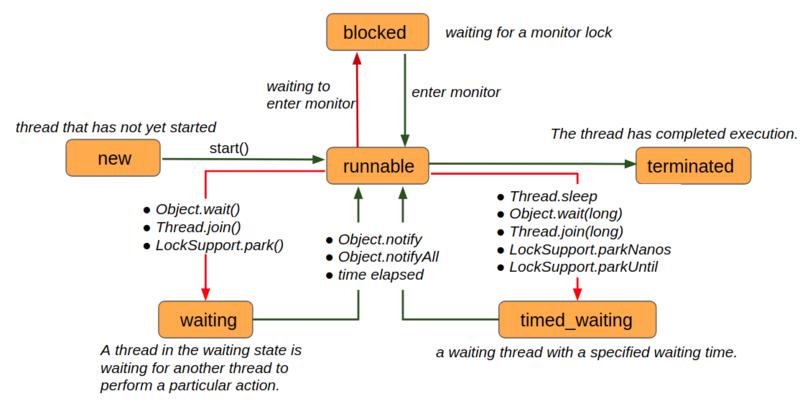
- new创建进入初始状态,start方法进入就绪状态。线程只要抢占了CPU时间片就能不获得全部的锁运行,但当运行到需要的锁而仍未获得时,进入阻塞状态。
- 线程被Sleep后,会先进入超时等待状态,时间结束后会先进入等待阻塞状态,当有锁以后再进入就绪状态
- java.lang.Thread.State
```java
/**
* A thread state. A thread can be in one of the following states:
* <ul>
* <li>{@link #NEW}<br>
* A thread that has not yet started is in this state.
* </li>
* <li>{@link #RUNNABLE}<br>
* A thread executing in the Java virtual machine is in this state.
* </li>
* <li>{@link #BLOCKED}<br>
* A thread that is blocked waiting for a monitor lock
* is in this state.
* </li>
* <li>{@link #WAITING}<br>
* A thread that is waiting indefinitely for another thread to
* perform a particular action is in this state.
* </li>
* <li>{@link #TIMED_WAITING}<br>
* A thread that is waiting for another thread to perform an action
* for up to a specified waiting time is in this state.
* </li>
* <li>{@link #TERMINATED}<br>
* A thread that has exited is in this state.
* </li>
* </ul>
*
* <p>
* A thread can be in only one state at a given point in time.
* These states are virtual machine states which do not reflect
* any operating system thread states.
*
* @since 1.5
* @see #getState
*/
public enum State {
/**
* Thread state for a thread which has not yet started.
*/
NEW,
/**
* Thread state for a runnable thread. A thread in the runnable
* state is executing in the Java virtual machine but it may
* be waiting for other resources from the operating system
* such as processor.
*/
RUNNABLE,
/**
* Thread state for a thread blocked waiting for a monitor lock.
* A thread in the blocked state is waiting for a monitor lock
* to enter a synchronized block/method or
* reenter a synchronized block/method after calling
* {@link Object#wait() Object.wait}.
*/
BLOCKED,
/**
* Thread state for a waiting thread.
* A thread is in the waiting state due to calling one of the
* following methods:
* <ul>
* <li>{@link Object#wait() Object.wait} with no timeout</li>
* <li>{@link #join() Thread.join} with no timeout</li>
* <li>{@link LockSupport#park() LockSupport.park}</li>
* </ul>
*
* <p>A thread in the waiting state is waiting for another thread to
* perform a particular action.
*
* For example, a thread that has called <tt>Object.wait()</tt>
* on an object is waiting for another thread to call
* <tt>Object.notify()</tt> or <tt>Object.notifyAll()</tt> on
* that object. A thread that has called <tt>Thread.join()</tt>
* is waiting for a specified thread to terminate.
*/
WAITING,
/**
* Thread state for a waiting thread with a specified waiting time.
* A thread is in the timed waiting state due to calling one of
* the following methods with a specified positive waiting time:
* <ul>
* <li>{@link #sleep Thread.sleep}</li>
* <li>{@link Object#wait(long) Object.wait} with timeout</li>
* <li>{@link #join(long) Thread.join} with timeout</li>
* <li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li>
* <li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li>
* </ul>
*/
TIMED_WAITING,
/**
* Thread state for a terminated thread.
* The thread has completed execution.
*/
TERMINATED;
}
线程如何设置优先级
- 给线程设置优先级,最大10,最小1,优先级设置完成后,只是增大了被cpu调度的机会,并不是绝对优先执行
- Thread.setPriority(10)
什么是竞争条件?你怎样发现和解决竞争
什么是竞争条件
- 多线程不确定的执行顺序导致不正确的结果,就是竞争条件
你怎样发现和解决竞争
发现
使用Java竞争条件坚持工具,如Facebook开源的RacerD
解决
可以采用加锁的方式使线程串行访问临界区
在Java中CyclicBarrier和CountdownLatch有什么区别
| 区别 | CountDownLatch | CyclicBarrier |
|---|---|---|
| 计数方式 | 递减计数 | 加法计数 |
| 可重复利用性 | 不可重复利用 | 可重复利用 |
| 初始值 | 初始值为N, N>0 | N为0 |
| 计数方式 | 调用countDown, N-1 | 调用await, N+1 |
| 阻塞条件 | N>0,调用await一直阻塞 | N小于指定值 |
| 何时释放等待线程 | 计数为0时 | 计数达到指定值N |
你知道哪几种锁?分别有什么特点?
偏向锁/轻量级锁/重量级锁
特指synchronized锁状态,通过对象头中的mark word表明锁状态
- 偏向锁:当线程获取锁时,打上标记,不做其他事
- 轻量级锁:多线程情况下,并发竞争锁或短时间竞争锁,通过CAS即可获取,当锁被其他线程获取时,自旋等待获取锁,不进行阻塞
- 重量级锁:自旋达到16次时还未获取到锁,则升级为重锁,线程进入阻塞状态
可重入锁/非可重入锁
- 可重入锁:当前线程已经持有这把锁,可以不释放这把锁情况下,再次获取这把锁。如ReentrrantLock
- 不可重入锁:当前线程持有这把锁,需要先释放,才能再次获取这把锁
共享锁/独占锁
- 共享锁:一把锁可以被多个线程共同持有
- 独占锁:一把锁只能被一个线程持有
公平锁/非公平锁
- 公平锁:线程拿不到锁情况下进入等待队列顺序获取锁
- 非公平锁:线程拿不到锁,在锁释放时争抢锁
悲观锁/乐观锁
- 悲观锁:获取资源之前必须先拿到锁,其他未能获取锁的线程无法影响当前线程
- 乐观锁:利用CAS,不独占资源状态下,完成对资源的修改
自旋锁/非自旋锁
- 自旋锁:线程拿不到锁时,进入循环无限请求锁资源直至获取
- 非自旋锁:拿不到锁就放弃/处理其他逻辑
可中断锁/不可中断锁
- 可中断锁:获取锁过程中突然要不想获取了,可以中断后做其他事,不需要一直等待获取锁。ReentrantLock就是可中断锁,打断方法为lockInterruptible
- 不可中断锁:一旦申请锁,只能一直等待直到获取成功,中途不可执行其他事件。Synchronized修饰的锁就锁不可中断锁
synchronized为什么是重量级锁,从系统层面讲
- synchronized加锁操作底层依赖操作系统的pthread_mutex_lock,多个线程同时调用这个函数时,会让每个线程都切换入内核态,由内核协调哪个线程获取到锁。
- 线程竞争调用系统底层Mutex互斥语句,存在用户态和内核态的转换,大量消耗系统资源,因此在系统层面称为重量级(Heavyweight)的操作
synchronize锁有几种
- 普通方法(对象级别)
- 静态方法(全局锁)
- 代码块(需指定一个对象,this为每个对象加锁,xxx.class使用某个类加锁)
synchronize锁是安全的吗
TODO
线程加锁有哪些方式?synchronized和lock的区别?Lock接口比synchronized块的优势是什么?
- 线程加锁有哪些方式
- synchronized keyword
- Lock Interface
- Semaphore
- CountDownLatch
- CyclicBarrier
- so on
- synchronized和lock的区别
- synchronized是JVM内置,Lock是juc实现
- synchronized只能使用内置monitor锁,Lock有多种实现
- synchronized是非公锁,Lock可公平可非公平
- synchronized可以自动释放,Lock需要手动释放
- Lock实现了可中断、可重入和定时锁获取功能
- Lock接口比synchronized块的优势是什么
- 可中断
- 可定时获取锁
- 多种实现
- 可选公平非公
JUC提供的锁与synchronized有什么区别
- 可重入性:JUC和synchronized都支持可重入,但synchronized用的是Monitor,JUC用的是state记录重入次数。JUC的锁需用户主动释放锁
- 可中断性:JUC可中断,synchronized不可中断
- 公平锁:synchronized默认非公锁
- 性能:低并发下synchronized可能更好,高并发JUC可能更好
- 灵活性:JUC更灵活
Java 11 的synchronized锁升级
Java 11 用在代码块进入和退出时,手动选择轻量级锁,从而提高性能。
并非取消锁升级,而是优化synchronized性能
synchronized加在多个非静态函数,函数之间什么关系
TODO
乐观锁和悲观锁的本质区别
乐观锁
不锁住对象,使用数据比对确认数据是否被修改,若修改则报错/重试
悲观锁
先获取锁,其他线程无法在此时争抢锁
CAS for循环过于消耗cpu怎么办,如何实现公平队列?
TODO
ReentrantLock# condition
volatile是否能保证线程安全
单volatile不可以
它只能保证可见性和有序性,不能保证原子性。它可以保证一个线程变更的数据立即写入主内存,确保其他线程的可见性。同时,可以防止Java语言编译后的指令重排序,保证有序性。
但是,如果需要多个操作同时具有原子性,无法保证,需要用锁或原子类
CAS+volatile+Atomic可以保证
伪共享 (False Sharing) 怎么理解
- 多个线程同时访问同一块缓存中不同的变量/对象,导致每次更新缓存时,都会使其他线程的缓存行失效,导致不必要的缓存同步,最终导致性能损失
- 可以通过调整变量的位置或者在变量之间插入padding,使不同变量之间占用不同的缓存行,避免缓存同步(如@Contended 但需测试优化)
需要实现一个高效的缓存,该缓存允许多个用户读,但只允许一个用户写,以此来保持它的完整性,如何实现
ReentrantReadWriteLock
支持多线程读,单线程写
为什么多线程会带来性能问题
- CPU分页。不合理线程的设置。
线程池中的线程调度,负载太大怎么办
优化线程池参数
减少核心树降低开销等
负载均衡策略
将同一线程池任务分配到多个线程池执行或者中间件扩容
优化任务处理
优化调用的任务减少线程负载
线程池基本原理、使用场景、注意事项、关联的连接池
TODO
线程池线程管理AQS
TODO
线程池阻塞非阻塞
阻塞
遇到IO将发生阻塞,程序遇到阻塞操作就停在原地,立即释放CPU资源
非阻塞
没有遇到IO操作,或者通过某种手段让程序即使遇到IO操作也不会停在原地执行其他操作,力求尽可能多占CPU
线程池Cancel策略
TODO
线程池的背压
- 有界队列满时抛出异常,及时给上游反馈
Java线程池与Tomcat线程池异同
Java线程池
当线程池中线程数量小于corePoolSize,每来一个任务,就会创建一个线程执行这个任务。
当前线程池线程数量大于等于corePoolSize,则每来一个任务。会尝试将其添加到任务缓存队列中,若是添加成功,则该任务会等待线程将其取出去执行;若添加失败(一般来说任务缓存队列已满),则会尝试创建新的线程执行。
当前线程池线程数量等于maximumPoolSize,则会采取任务拒绝策略进行处理。
Tomcat线程池
当前线程数小于corePoolSize,则去创建工作线程;
当前线程数大于corePoolSize,但小于maximumPoolSize,则去创建工作线程;
当前线程数大于maximumPoolSize,则将任务放入到阻塞队列中,当阻塞队列满了之后,则调用拒绝策略丢弃任务;
Thread.sleep(), Object.wait(), LockSupport.park(),Condition.await()区别
- Thread.sleep()
- 必须指定休眠时间
- 休眠时线程状态为TIME_WAITING
- 需要捕获InterruptedException异常
- 不会释放持有的锁
- 只能等待自己到时间后醒来,唤醒后一定执行后续代码
- 本身是一个Native方法
- 通常被用于暂停
- Object.wait()
- 不带时间的重载可以通过Thread.notify()唤醒,也可以等待超时唤醒。notify()必须在wait()之后执行,否则会丢失唤醒信号
- 唤醒后不一定执行后续代码
- 休眠时线程状态为WAITTING
- 需要捕获InterruptedException异常
- 会释放持有的锁
- 调用Object.wait()时需先上锁,JVM底层会进行检查是否上锁,没持有则抛出IllegalMonitorStateException异常 synchronized (waitObject){waitObject.wait()}
- 调用Object.notify()时也需要上锁,否则如果当前线程不是对象锁的持有者,该方法抛出一个IllegalMonitorStateException异常。
- wait(TimeOut)是一个Native方法
- 通常被用于线程间交互
- LockSupport.park()
- 通过二元信号量实现的阻塞
- 底层调用的是UnSafe的Native方法park()
- 休眠时线程状态为WAITING
- 无需捕获InterruptedException异常,但也会响应中断
- 不会释放持有的锁
- 可以通过unpark()唤醒, unpack()方法可以比 park() 先执行,不会丢失唤醒信号
- 唤醒后一定执行后续代码
- Condition.await()
- 不带时间的重载只能通过另一个的Condition.single()唤醒,唤醒后不一定执行后续代码
- await还是single都必须先ReentreentLock的lock()块中执行,否则IllegalMonitorStateException异常
- single不能在其之前执行
- 需要捕获InterruptedException异常
- 会释放锁资源
- 底层调用LockSupport.park()实现
Java中怎样唤醒一个阻塞的线程
- Object.wait()使用Object.notify()唤醒。必须配合synchronized使用
- Condition.await()使用Condition.singal()唤醒。需搭配ReentrantLock使用
- LockSupport.park()使用LockSupport.unpark()唤醒。
wait与await区别
- wait与notify必须配合synchronized使用,因为调用之前必须持有锁,wait会立即释放锁,notify则是同步块执行完了才释放
- 因为Lock没有使用synchronized机制,故无法使用wait方法区操作多线程,所以使用了Condition的await来操作
- Lock实现主要是基于AQS,而AQS实现则是基于LockSupport,所以说LockSupport更底层,所以使用park效率会高一些
Thread.sleep(0)目的
- 让GC线程有机会被操作系统选中,从而进行垃圾清理工作。但可能导致频繁GC问题
- https://blog.csdn.net/u012060033/article/details/126781986
Thread.yield()
- 使线程让出当前被调度机会
- 但是与Thread.sleep()不考虑线程优先级问题,谁都有机会抢到下一次机会。yield()只会给同等优先级或更高的线程运行
- 调用sleep()进入阻塞状态,yield()进入就绪状态,yield可能会再运行一小会儿才交出机会
- sleep抛出InterruptedException,yield无异常。
在Java进程中的通信方式有哪些
TODO
在Java中线程间有哪些通信方式
- volatile,synchronized关键字
- join() 方法
- ThreadLocal
- 等待/通知 Object.wait() Object.notify()/notifyAll()
- 管道输入输出流
多进程与多线程的区别
TODO
为什么AtomicInteger在高并发下性能不好
- 性能不好原因
- CAS竞争激烈
- 缓存行伪共享
- 解决策略
- 减少竞争:ThreadLocal或分段锁减少对同一个AtomicInteger对象竞争
- 避免缓存行伪共享:可以利用
缓存行填充技巧,在AtomicInteger对象前后填充数据增加缓存行大小
有哪些解决死锁问题的策略
- 死锁必要条件
- 互斥:一个资源每次只能被一个进程使用
- 请求与保持:一个进程因请求资源而被阻塞时,对已获得的资源保存不放
- 不剥夺:进程已获得的资源,在未使用完前,不能强行剥夺
- 循环等待:若干进程之间形成一种头尾相接的循环等待资源关系
- 死锁解决策略
- 预防死锁:设计算法或协议避免死锁发生,如顺序申请锁,避免嵌套、限制资源分配
- 检测死锁:使用死锁检测算法(如银行家算法)检测死锁
- 避免死锁
- 解除死锁
有哪些线程安全问题
竞态条件 (Race Condition)
执行顺序不确定或时间差原因,导致结果出现不同情况
- 使用Atomic类解决
死锁(Deadlock)
多线程互相等待对方释放锁
数据不一致(Inconsistent Data)
多个线程同时对共享资源进行修改,最终导致结果不一致
- volatile配合Lock解决
内存泄漏(Memory Leak)
某个对象被多个线程引用,其中一个线程将对象引用设置为null,导致其他线程无法访问,但该对象无法被垃圾回收
- 与ThreadLocal不同,由于某些原因无法释放内存,而ThreadLocal的K为null且V未被其他引用时,最终仍可回收,V被引用且线程一直存在才无法回收
Double Check Lock问题
volatile解决
并发修改异常 (ConcurrentModificationException)
迭代集合时,若有其他线程修改了集合,则抛出异常
重排序问题
volatile解决
线程池有哪几种拒绝策略
- AbortPolicy:中止策略,线程池会抛出异常并中止执行此任务;
- CallerRunsPolicy:把任务交给添加此任务的(main)线程来执行;
- DiscardPolicy:忽略此任务,忽略最新的一个任务;
- DiscardOldestPolicy:忽略最早的任务,最先加入队列的任务。
- new RejectedExecutionHandler 自定义
一个线程两次调用start()方法会出现什么情况
IllegalThreadStateException
原因:start state状态已变更
1
if(state != 0) throw new IllegalThreadStateException
线程如何中断
线程请求中被请求中止或中断。调用Interrupt()方法,它使中断标志位为true
线程可以通过isInterrupted()方法来判断中断标志是否被设置。
此外,还可以通过Thread类的静态方法interrupted()来判断中断标志是否被设置,并且该方法会清除中断标志。
当一个线程调用了一个阻塞方法时(如sleep()、wait()、join()等),如果该线程的中断标志被设置,那么该方法会立即抛出InterruptedException异常,同时清除中断标志。在抛出InterruptedException异常后,线程就可以选择退出或者继续执行。如果线程继续执行,那么它的中断标志仍然会被设置为true。
线程如何停止
使用标识位,在线程中不断检测该标志位,如果标志位被设置,则退出线程
1
2
3
4
5
6
7
8
9
10
11
12
13public class MyThread extends Thread {
private volatile boolean stop = false;
public void stopThread() {
stop = true;
}
public void run() {
while (!stop) {
// 线程逻辑
}
}
}
线程读写资源,在不使用锁的情况下高效实现
线程安全数据结构
如
ConcurrentHashMap、CopyOnWriteArrayList等。这些数据结构本身就是线程安全的,可以直接用来读写共享资源。原子类操作 共享资源变量
如
AtomicInteger、AtomicLong、AtomicReference等,它们都提供了一些原子性的操作方法,可以保证对共享变量的读写是线程安全的,不需要加锁。线程安全的并发数据结构
如
BlockingQueue、ConcurrentLinkedQueue等。这些数据结构提供了一些特殊的操作方法,可以用来实现生产者-消费者模式,可以在不使用锁的情况下实现线程间的协作。
ThreadLocal是什么?在工作中用到过ThreadLocal吗?
ThreadLocal是什么
关联线程与对象的关系,使线程拥有自己独立的变量副本,避免多线程安全问题
工作中的使用
用于上下文传递信息,如Token,Session等
ThreadLocal怎么实现的
- ThreadLocal基于ThreadLocalMap,每个Thread对应一个ThreadLocalMap对象,用于存储ThreadLocal变量和对应的值
- 当线程调用ThreadLocal的set方法,实际上就是通过当前线程对象的ThreadLocalMap对象将ThreadLocal对象和对应的值存储到了其中。如果需要访问该值,会通过Thread对象获取对应的ThreadLocalMap,再从ThreadLocalMap获取Value,保证线程安全性
- ThreadLocal的key是Weak类型的,理论上会被GC,但如果是多线程环境,可能由于线程池化导致数据不GC,或者Value被强引用导致无法GC,最终导致Memory Leak
ThreadLocal 内存泄露是怎么回事
- 多线程环境下,每个线程有一个自己的ThreadLocalMap实例,而ThreadLocalMap中的Entry对象会持有ThreadLocal的强引用,如果线程池化且对应的ThreadLocal对象未被回收,就会一直存在于内存中,导致Memory Leak
- 如果使用完ThreadLocal后,没有显示调用remove()方法,即使Key是weak类型,但若Value被外部强引用,也会导致数据一直存在,最终导致OOM
ThreadLocalMap的结构了解吗?扩容机制了解吗?
结构
基于开放地址法的线性探测哈希表,它的实现中使用了一个Entry数组存储K-V。每个Entry包含2个熟悉,Key和Value,分别表示线程本地变量的键和值。
ThreadLocalMap中的键是ThreadLocal对象,值是ThreadLocal对象关联的值,由于ThreadLocalMap是线程私有的,因此每个线程都会持有一个ThreadLocalMap对象
扩容机制
当ThreadLocalMap中的Entry数量达到阈值,会使用resize()方法对数组进行扩容,扩容时需重新计算每个Entry在数组中的索引位置,如果在新数组中该Entry已被占用,则使用线性探测法查找到下一个位置
ThreadLocal父子线程怎么共享数据?
当一个线程启动一个新的子线程时,新线程会继承父线程中的ThreadLocalMap对象,并在该Map对象中创建一个新的Entry对象。在新线程中,可以通过ThreadLocal对象来访问该Map对象中的Entry对象,从而获取到父线程中设置的ThreadLocal变量的值。
具体来说,可以通过以下步骤实现父子线程之间的数据传递:
- 在父线程中创建并设置ThreadLocal变量的值。
- 在子线程中通过ThreadLocal对象访问父线程中的ThreadLocalMap对象,并获取到父线程中设置的ThreadLocal变量的值。
hreadLocal对象的作用域仅限于当前线程中。因此,如果想要在子线程中修改父线程中设置的ThreadLocal变量的值,需要在父线程中将该变量设置为可变对象,并使用同一个可变对象的引用来修改其属性值。这样,在子线程中就可以通过ThreadLocal对象获取到该可变对象,并修改其属性值,从而实现父子线程之间的数据共享。
ThreadLocal有JMM内存屏障问题吗
- ThreadLocal中每个线程拥有自己私有变量,不需要同步,因此没有JMM内存平常问题
为什么大厂规定不能使用Executors去创建线程池?
FixedThreadPool
keepAliveTime为0,无限等待,且LinkedBlockingQueue,可能导致OOM
SingleThreadExecutor
keepAliveTime为0,无限等待,且LinkedBlockingQueue,可能导致OOM
CachedThreadPool
最大线程数为Integer.MAX_VALUE,可能导致OOM
ScheduledThreadPool和SingleThreadScheduledExecutor
keepAliveTime为0,DelayedWorkQueue也是无界队列,因此可能OOM
如何根据实际需要,定制自己的线程池?
《Java并发编程实战》的作者 Brain Goetz 推荐的计算方法:
1
线程数 = CPU 核心数 *(1+平均等待时间/平均工作时间)
Pool大小:线程池太小会进入等待对象,太大会占用过多切换资源
WorkQueue:过小无法进入队列,过大导致内存占用大
Reject:过于严格可能线程无法执行,过于宽松可能导致资源占用大
Thread-Factory:根据需求定制工厂,自定义名称、Policy,守护线程以及异常线程处理
为什么需要 AQS?AQS 的作用和重要性是什么?
AQS(AbstractQueuedSynchronizer)是 Java 并发包中一个非常重要的组件,它提供了一种实现同步器的基础框架。在 Java 并发包中,Lock、ReentrantLock、Semaphore、CountDownLatch 等同步工具类都是通过 AQS 实现的。
AQS 的作用和重要性可以总结为以下几点:
- 提供了一种实现同步器的基础框架:AQS 通过提供一些同步器的基本方法,如获取锁、释放锁、阻塞等待等,让开发人员能够更方便地实现各种同步器,如锁、信号量、倒计时门栓等。
- 支持独占锁和共享锁:AQS 支持独占锁和共享锁两种模式,独占锁模式适用于只有一个线程可以获得锁的情况,如 ReentrantLock,而共享锁模式适用于多个线程可以同时获得锁的情况,如 CountDownLatch。
- 高效的等待/唤醒机制:AQS 内部维护了一个同步队列,通过将等待线程加入到同步队列中,并使用 CAS 操作进行等待线程的唤醒和阻塞,实现了高效的等待/唤醒机制。
- 支持条件变量:AQS 提供了 Condition 类,通过 Condition 可以实现更高级别的线程通信机制,如生产者/消费者模式。
因此,AQS 的作用和重要性在于提供了一种实现同步器的基础框架,并且支持独占锁和共享锁模式,提供了高效的等待/唤醒机制和支持条件变量,是 Java 并发包中实现各种同步器的基础。
多线程的信号量如何
TODO
AQS和ReentrantLock的关系
TODO
CAS是一种什么样的同步机制?
- Compare And Swap
你知道CAS 有什么缺点?
- ABA问题
- 循环时间长开销
- 只能保证一个变量的原子操作
- 多个变量操作时,使用互斥锁保证原子性
- 将多个变量封装成对象,通过AtomicReference保证原子性
你知道线程池实现“线程复用”的原理吗?
- 启动一部分线程,池化保存到线程池中,当需要处理任务时,取出一个空闲线程执行任务,执行完毕后放回线程池并不销毁
阻塞和非阻塞队列的并发安全原理是什么?
- 都是基于原子操作和同步机制实现的
- 对于阻塞队列,当队列满时,插入操作会被阻塞,直到队列中有空闲位置;当队列为空时,删除操作会被阻塞,直到队列中有元素。阻塞队列通常使用Condition和ReentrantLock来实现,其中Condition是对应于ReentrantLock的等待/通知机制,通过await()方法等待信号并释放锁,signal()方法唤醒等待的线程。
- 对于非阻塞队列,插入操作和删除操作都是非阻塞的,当队列满或者为空时,插入操作和删除操作都会返回失败或者null。因此,非阻塞队列通常采用并发原子操作CAS和volatile变量来实现。
- 需要注意的是,阻塞队列和非阻塞队列都需要保证并发安全,否则会导致线程安全问题。对于阻塞队列,由于涉及到等待/通知机制,因此实现比较复杂;对于非阻塞队列,由于涉及到并发原子操作,因此实现比较高效。
你对“公平锁”了解吗?为什么会有“非公平锁”?
公平锁
FIFO
原因
业务需求和性能考虑,一些要求需要FIFO场景。但是维护FIFO队列需要性能,如notify()唤醒下一个线程。如果不需要FIFO场景,使用非公锁可以更好抢占资源,提高性能
你对“自旋锁”了解吗?优缺点分别是什么?
基于忙等待的锁,利用CAS实现原子操作,不需要加锁和解锁动作,调度延迟低,减少线程切换开销
自旋锁在第一层未获取资源情况下,会开始自旋,直到被释放或自旋一定次数后,才会升级轻量锁或重锁。轻量锁也是基于CAS,通过Object Head上设置标志位和指针实现。重锁使用系统提供的mutex或者spinlock实现
优点
不需要加锁没锁操作,减少锁开销,减少线程切换和调度延迟
缺点
一直自旋会导致CPU资源被消耗
CPU 核心数和线程数的关系?
- 单核处理器:单核处理器只有一个物理处理单元,只能同时执行一个线程,因此线程数为1。
- 多核处理器:多核处理器有多个物理处理单元,每个物理处理单元可以同时执行一个线程,因此线程数等于核心数。
多线程环境中遇到的常见的问题是什么?怎么解决?
- 线程安全问题:锁、Atomic类、Concurrent容器
- 死锁:避免嵌套,按照顺序执行,使用超时机制
- 性能问题:控制线程新增销毁次数,减少锁竞争,使用非阻塞算法等
- 内存泄漏问题:如ThreadLocal,显示调用remove()方法
- 可见性问题:指令重排序和缓存一致性的原因,导致普通变量被修改无法被其他线程看到。使用volatile或synchronized等
- 阻塞问题:使用非阻塞IO,使用异步模型
在Java中绿色线程和本地线程区别
- 绿色线程为早期无法映射到OS线程而在JVM上建立的用户态线程,需要JVM进行调度
- 已被取代,目前完全是内核态线程
死锁与活锁的区别,死锁与饥饿的区别
- 死锁:两个线程互相持有对方需要的资源,一直等待
- 活锁:没有被阻塞,但因缺少必要条件,一直无限重试,线程状态会一直变更
- 饥饿锁:高优先级线程一直抢占资源,低优先级线程无法获取资源而饥饿。当高优先级线程结束后可以恢复
Java中用到的线程调度算法是什么
- 分时调度
- 抢占式调度(Java默认)
在线程中怎么处理不可捕捉异常
- 实现Thread.UncaughtExceptionHandler自定义异常处理器捕获s
什么是线程组,为什么在Java中不推荐使用
- 线程不安全
- resume、suspend等方法会导致DeadLock问题,已被官方废弃
为什么使用Executor框架比使用应用创建和管理线程好
- 控制线程总数,控制并发数量
- 复用线程
在Java中Executor和Executors的区别
- Executor有子类ExecutorService,可自定义线程池,子类支持Runnable和Callable方法
- Executors为官方线程池
方法中的参数在内存中的传递过程,详细的
TODO
从excel表中批量 (10w+) 导入数据。解决方案
TODO
如何在Windows和Linux上查找哪个线程使用的CPU时间最长
- Jstack查询CPU使用最多的PID编号
Other
如何用10行代码实现一个负载均衡服务
- Servlet 代码中调用响应重定向方法
百万文件,每个文件有很多汉字,每个文件大小不同。假设1000个汉字,问怎样统计出这些文件里出现次数最多的汉字
- Hash笔记,求出每个小文件中重复次数最多的,再整合后统计
- BitMap记录
JAVA LIST查询过大容易OOM解决方案
- 分页,分Batch处理
- 调整Heap大小参数
用Java编程一个会导致死锁的程序,怎么解决
- 避免锁嵌套
- 避免长时间持有锁,使用
wait()和notify()等方法进行线程之间的协调。 - 设置超时时间
File IO相关
Java几种Copy方式,哪种效率最高
Copy方式
- 字节流 FileInputStream/FileOutputStream
- 字符流 FileReader / FileWriter
- 缓冲流 BufferedInputStream / BufferedOutputStream
- NIO流 FileInputStream / FileOutputStream ->getChannel
效率最高
NIO 流
JMM 相关
JMM模型
TODO
volatile模型
TODO
刷写数据synchronized和volatile异同
TODO
什么是“内存可见性”问题
TODO
你知道主内存和工作内存的关系?
TODO
你知道什么是 happens-before 原则吗?
TODO
JAVA创建对象时是否存在窗口期
- Memory Order
共享内存在 JAVA中是怎么体现的
TODO
Java里面的内存模型和操作系统里面的内存模型有什么区别
TODO
JVM 相关
JVM结构
TODO
JVM内存分配的过程
TODO
对象的内存布局
TODO
Java运行时区域中哪些是线程共享的哪些是线程私有的
TODO
程序计数器作用
TODO
虚拟机栈里面是什么
TODO
方法区存储什么内容
TODO
Java栈什么时侯会发生内存溢出
TODO
内存碎片怎么优化
TODO
JVM GCRoots对象
- 虚拟机栈(栈帧的本地变量表)引用的对象
- 本地方法栈JNI引用的对象
- 方法区中类静态属性引用对象
- 方法区中常量引用对象
- 被synchronized锁持有的对象
- 基本数据类型对应的Class对象、常驻对象、类加载器
- 反映JVM内部情况的JMXBean等
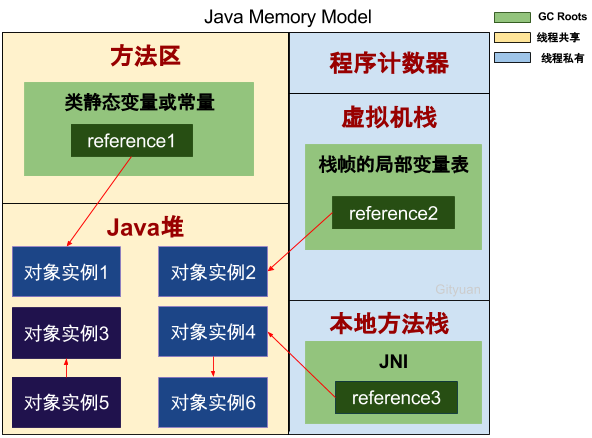
什么是不可达
通过一系列GC Root对象作为起点向下搜索,搜索时走过的路径称为引用链 (Refrence Chain),当一个对象到GC Root没有任何引用链相连时,则认为该对象不可达,会被GC回收
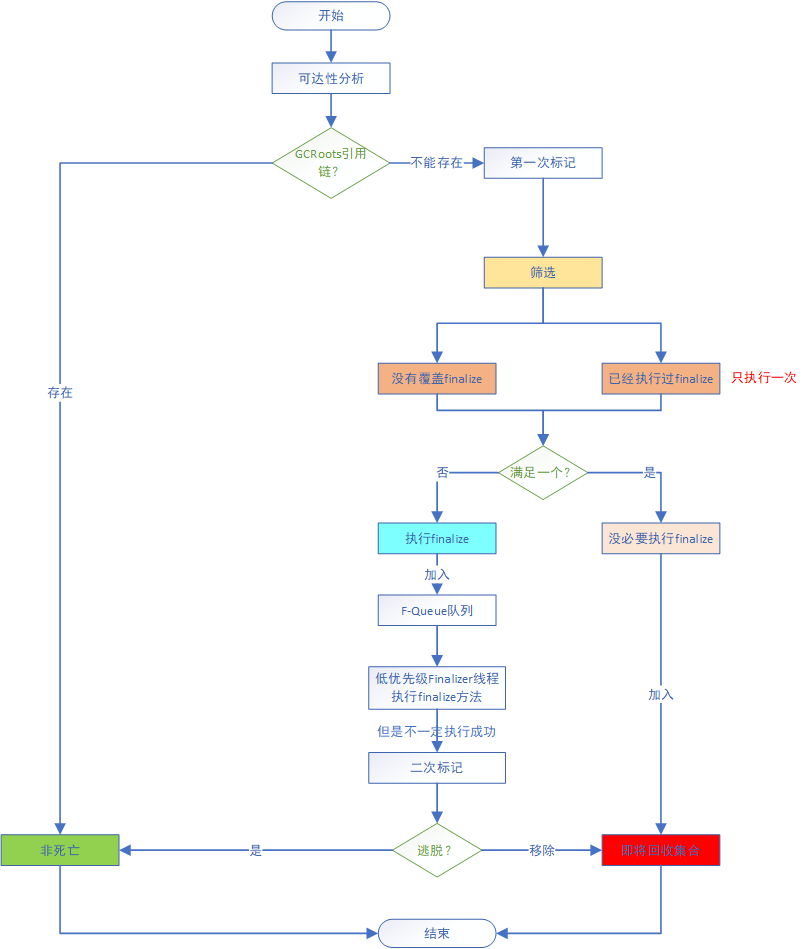
A、B对象可回收,一定就会被回收吗
不一定,要看是否执行过finalize()方法,没执行但有必要执行的对象放入F-Queue,虚拟机建立一个优先级低的Finalizer线程对F-Queue中的对象进行finalize()方法,之后F-Queued对其二次标记,如果没能逃脱则回收
为什么要分Young Gen and Old Gen
- 提升回收效率
- Heap Space 分为
Old Gen和Young Gen,新生代又包含Eden Gen和Survivor Gen - 新对象正常情况下很快会被回收,因此GC可以主要集中在Young Gen
- Eden Space 是创建新对象的空间,如果触发GC,存活的会进入Survivor Space
- Suivivor Space空间的对象在一定次数还未被回收后,会进入Old Gen
- Old Gen通常比Young Gen大,因为要存放长期生命周期的对象
- Old Gen 和 Young Gen比例大概是70%和30%,其中Survivor Space占用 10%-20%,剩下的分配给Eden Space。但需具体问题具体分析
为什么用元空间替换永久代
- PermGen在堆内,大小不可变,可能出现OOM
- MetaSpace在JVM中,大小可自由变化
GC会清除方法区数据吗
Java7 中,PermGen存放于方法区,是堆空间的一部分,GC会清除。
Java8后
划分到元空间,是独立于堆的空间,用于存储类元数据、驻留字符串和其他非堆 JVM 数据。
一般来说,它有自己的回收方式,不由Heap GC直接管控。
某些情况下,GC可能间接释放方法区中的空间,如:不再需要某个类,GC可能会回收类实例及其相关元数据的使用内存,从而释放方法区中的空间。
元空间不受固定大学限制,JVM会根据元数据量自动调整大小
最大堆内存和最小堆内存如何配置
TODO
一个固定的堆内存,当线程数创建很多时,JVM参数如何设置
TODO
调优
TODO
Class文件包括哪些
TODO
ClassLoader相关
简单说说你了解的类加载器,可以打破双亲委派么?
负责在运行时将 Java 类加载到内存中。 Java ClassLoader遵循Parent Delegation Model,即它首先将类加载请求委托给它的父类加载器,如果父类加载器找不到该类,则尝试从自己的资源中加载该类。
Bootstrap ClassLoader - 从
/lib 目录或 JDK9 及更高版本中的 jrt:// 文件系统加载核心 Java 类。 Extension ClassLoader - 从扩展目录(通常是
/lib/ext)加载类。 System/Application ClassLoader - 从应用程序类路径加载类,这可以通过 -classpath 或 -cp 选项或 CLASSPATH 环境变量进行设置。
每个ClassLoader都有一个parent ClassLoader,除了Bootstrap ClassLoader,它是root ClassLoader。 Parent Delegation Model 确保同一个类不会被不同的 ClassLoader 多次加载,这可能会导致 ClassCastExceptions 和其他运行时错误。
可以,类似Tomcat,为了实现多个内部容器,必须打破双亲委派,可以提升控制颗粒度和灵活度。
双亲委派最终是由父类加载还是子类加载
TODO
如果打破双亲委派机制,加载了不同系统同名类会有什么问题
- 如果双亲委派机制被破坏,并且加载了来自不同系统的同名类,则可能导致 ClassLoader 冲突和运行时的意外行为。
父类加载器和子类加载器在代码上是什么关系
TODO
如果我想自己控制类加载的时机怎么办
TODO
如果创建一个java.lang.String类,这个类是否可以被类加载器加载
- 默认不行,bootstrap默认JVM加载java.*的类(双亲委派机制保护)
- 可以通过修改父类findClass方法加载,不建议
JVM是如何处理异常的
在一个方法中如果发生异常,这个方法会创建一个异常对象,并转交给JVM。该异常对象包含:异常名称,异常描述以及异常发生时应用程序的状态。创建异常对象并交给JVM的过程叫做抛出异常。可能有一系列的方法调用,最终才进入抛出异常的方法,这一系列方法调用的有序列表叫做调用栈。
JVM会顺着调用栈去查找是否有可以处理异常的代码,如果有,则调用异常处理代码。如果没有找到,JVM就会将该异常转交给默认的异常处理器(默认处理器是JVM的一部分)默认异常处理器会打印出异常信息并终止程序运行。
finnal、finnally、finalize的区别
finnal可以修饰类、变量、方法;修饰类,则该类不能被继承;修饰变量,则表示该变量是一个常量,不能被重新赋值;修饰方法,表示该方法不能被重写
finnally一般作用在try-catch代码中,在异常处理的时候,通常代码一定要执行的方法写在finnaly代码块中,通常写在finnally中的代码一定会被执行。一般写关闭资源的代码语句
finalize是一个方法,属于Object类,Object类是所有类的父类,java中允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作
Garbage Collection
JDK8 的默认垃圾回收器
- Parallel Scavenge(新生代)+ Serial Old(老年代)
CMS需要手动设置
对象是否可 GC
- GC Root可达性算法
GC什么时候启动
- Minor GC在Young Gen中Survivor 区域满时启动
- Full GC在 Old Gen 空间满时启动
Mutator
Mutator是 JVM 的一部分,但不是垃圾收集器的一部分,它负责为对象分配以及更新对象与 GC Roots 的关系。
Mutator记录关系是为了确保它不会改变不应该改变的对象。
例如,如果 Mutator 正在改变对象中的字段,它需要确保它不会同时改变与第一个对象相关的任何其他对象中的字段。如果这样做,可能会导致意想不到的结果。
FullGC 或者 MinorGC发生时,Mutator 会暂停执行
GC自己计算对象与GC Roots的关系并清楚,不使用Mutator记录的数据
Mutator不是必须的,如果对象关系不变更,就不需要使用Mutator
基本算法
引用计数
标记清除
复制收集
标记整理
分代收集
都是各种组合
垃圾收集器有哪几种
- Serial
- Serial
- Serial Old
- Parallel
- ParNew
- Parallel Scavenge(CMS)
- Parallel Old(CMS)
- Concurrent
- CMS
- G1
标记复制和标记整理算法的对比
标记复制
区分3个区域,Eden,S0,S1,建议比例8:1:1
一般用于Young Gen,新对象进入Eden,触发Minor GC,第一次随机进入S0或S1,后续存活对象从Eden进入Survivor区,且S0-S1存活对象相互复制,15次未被GC则进入Old Gen
标记整理
清除垃圾并将数据整理,减少碎片,但会有较长耗时
CMS是什么,简述工作流程
CMS是什么
垃圾收集器
简述工作流程
初始标记
并发标记
重新标记
标记清除
CMS新生代老年代算法
- Young Gen:Copy
- Old Gen:Mark-Sweep
为什么要分代回收,分代回收背后的思想
为什么要分代回收
弱分代假说(Weak Generational Hypothesis):绝大多数对象都是朝生夕灭的。
强分代假说(Stong Generational Hypothesis):熬过越多次垃圾收集过程的对象就越难以死亡。
跨代引用假说(Intergenerational Reference Hypothesis):跨代引用相对于同代引用来说仅占极少数。
分代回收背后的思想
不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率。一般把Java堆分为新生代和老年代,这样就可以根据各个年代的特点来使用不同的回收算法,以提高垃圾回收的效率。
CMS缺陷
CPU占用高
Old Gen使用mark-sweep会产生碎片,可用参数解决但会增加GC时间
-XX:+CMSIncrementalPacing 使 CMS GC 以较小的增量收集垃圾
-XX:+CMSFullGCsBeforeCompaction 强制 CMS Full GC多少次数后压缩
CMS回收为什么要停顿两次
- 初始标记,将所有GC Root连接对象标记,STW
- 并发标记,与用户线程同时,深度遍历,不暂停
- 重新标记,避免用户操作过程中变更对象引用关系,需要STW
- 并发清除
Young GC 的时候,主要操作哪些区块,Eden到S0 还是 S1区的过程是随机还是确定的
- Eden和survivor
- 第一次随机,后续确定,15次未收集的对象进入Old Gen
为什么配置了CMS GC仍然会触发Full GC
- 大对象Old Gen和Old Gen都放不下
- Old Gen 碎片过多
- GC失败
- 人为执行
G1的特性
TODO
G1的region被回收之后怎么解决内存碎片的
TODO
G1 GC 写屏障原理
TODO
G1 GC的Card Table、Remembered Set和存活对转移对象原理
TODO
G1垃圾回收器年轻代、老年代回收原理
TODO
GC调优
TODO
-xms,-xmx
内存泄漏和内存溢出区别
- 内存泄漏是生成的对象不被显示引用后,仍无法回收,Memory Leak
- 内存溢出是生成对象过多,JVM无法拥有更多空间,导致OOM
频繁Young GC原因
- Survivor Space过小
- 新对象创建太快,没有有效重用对象
如果出程序出现内存溢出,如何排查解决
Heap内存使用过多,通过
-Xmx和-Xms参数控制最大最小堆最小堆大量创建对象
查看是否有业务大量创建对象,如果出现大量创建和销毁,可能导致GC无法及时回收,内存溢出。尽量复用对象
集合类使用问题
程序中使用大量集合,且存储对象很大,都被引用或未及时回收会造成OOM。
优化队列大小,优化 ArrayList 替换 LinkedList、HashMap 替换 TreeMap 。
递归调用层过多
递归调用层数过多也可能导致内存溢出
Maven相关
Maven中dependencyManagement作用
- 负责子模块使用时的引入
A模块依赖B模块1.0版本,C模块依赖B模块1.1版本,现在A模块依赖C模块,问依赖B模块多少版本?
- 根据Maven依赖顺序决定,就近原则
Spring 相关
RestController与Controller区别
- @RestController = @ResponseBody + @Controller,无法返回指定页面
- @Controller可以返回指定页面,如果需要返回数据需要+ @ResponseBody辅助
RequestBody与ResponseBody区别
- RequestBody 入参
- ResponseBody 出参,将数据转化为JSON等格式返回
Spring底层实现
TODO
Spring事务底层实现
TODO
IOC理解
TODO
IOC主要容器
TODO
Spring生命周期
TODO
Spring Bean加载初始化过程
TODO
AOP原理
TODO
注解底层实现流程
TODO
BeanFactory与FactoryBean的区别
TODO
Beanfactory和ApplicationContext是什么关系,使用有什么区别
TODO
Spring 中如何让A和B两个bean按顺序加载
- @DependsOn() 注解
- 实现BeanFactoryPostProcessor,提前调用 init方法
Spring中Bean默认是Singleton还是多态的
- Singleton
为什么默认Singleton
- serverless
- 方法执行结束后,不改变类的状态,不变更全局参数
为什么@Scope提供prototype类型
TODO
Spring如何自定义注解
TODO
SpringMVC
SpringMVC工作流程
TODO
SpringMVC组件工作流程,如果不这么设计会有什么问题
TODO
检查拦截器的执行链路在哪个方法比对
TODO
Spring有几种依赖注入方式
- @Autowired
- Set
- Constructor
Spring有几种异步调用方式
TODO
JDK中的SPI机制是怎么实现的?Spring 实现的SPI了解过吗?
TODO
如果在一个类内部,我想用某个方法 A调用另一个方法B,想对被调用的方法B进行一个切面,怎么处理?
TODO
CSRF攻击是什么,原理以及如何防御
TODO
如何解决跨域,原理是什么
TODO
RPC进程通信方式有哪些方式
TODO
SpringMVC的跳转与重定向区别
TODO
Spring RestTemplate的具体实现
TODO
为什么 JDBC步骤mysql数据存储格式 spring 相关
TODO
JDBC 源码如何实现的
TODO
- 调用Class.forName()方法加载相应的数据库驱动程序;
- 定义要连接数据库的地址URL,要注意不同数据库的连接地址不同;
- 使用适当的驱动程序类建立与数据库的连接,调用DriverManager对象的getConnection方法,获得一个Connection对象,它表示一个打开的连接
- 创建语句对象;
- 执行语句;
Statement接口提供了3个方法执行sql语句,分别是executeQuery, executeUpdate和execute
executeQuery方法用于执行SELECT查询语句,并返回单个结果集,保存在Resultset对象中; - 对返回的结果集ResultSet对象进行处理;
- 关闭连接。
SpringMVC中的session如何拿到的
- RequestContextHolder获取Request,间接获取session
- HttpServletRequest获取session
不使用xml不使用注解如何动态注入Bean
Annotation
@Component
@Configuration
@Bean
事务
Service相互调用,被调用类已Catch异常,为何@Transactional仍然回滚
场景
@Transactional 在ServiceA 上注解,当ServiceA调用ServiceB,在ServiceB出现异常并捕获时,ServiceA落库的数据仍然抛出异常被回滚
原因
由于事务传播机制,ServiceB默认Propagation.REQUIRED传播方式,因此当ServiceB出现异常时,即使被捕获,仍然已被标记需要回滚
解决方案
ServiceB设置为Propagation.REQUIRES_NEW传播机制,同时取消ServiceB的捕获try-catch,移入serviceA调用serviceB的部分,由serviceA进行捕获即可
鉴权
Spring Security和Shiro区别
TODO
JWT 对比 cookie 和 session 有什么区别
TODO
Session可以存放Cookie吗
TODO
SSO与OAuth2.0区别
- SSO是单点登录,负责一次鉴权,多应用使用
- Oauth2.0是授予操作权限
- SSO是为了解决一个用户在鉴权服务器登陆过一次以后,可以在任何应用(通常是一个厂家的各个系统)中畅通无阻。OAuth2.0解决的是通过令牌(token)而不是密码获取某个系统的操作权限(不同厂家之间的账号共享)。
登录一般选择用Jwt还是 Redis
TODO
Redis 续期你们是怎么做的?难不成每次请求都重置过期时间吗?这不会存在一个安全问题吗
TODO
使用jiwt续期,因为有refresh token,这个只在登录和刷新才需要携带相对安全一点旦规定了登录最大时问,一般请求只需要access token,这个token有效时间很短相对安全可控。但是存在登录流程需要和前端配合且不能强制退出这个缺点
SpringBoot 相关
SpringBoot 的启动原理
TODO
Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含 了以下 3 个注解:
@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项
@ComponentScan:Spring组件扫描。
SpringBoot 生命周期
SpringBoot应用的生命周期,整体上可以分为SpringApplication初始化阶段、SpringApplication运行阶段、SpringApplication结束阶段、SpringBoot应用退出四个阶段。
Spring Boot 支持哪些日志框架?推荐和默认的日志框架是哪个?
- Log4j2,LogBack等
- 推荐使用LogBack
SpringBoot Starter的工作原理
- 解析Maven各个starter中的spring.factories文件,根据需求自动配置把Bean注入SpringContext中
SpringBoot 自动装配原理
TODO
@Bean注解和@Component区别
TODO
SpringBoot事务的使用
- 声明式:@Transactional(rollbackFor=Exception.class),这种方法可能出现事务失效问题
- 非声明式:TransactionTemplate
登陆的实现
TODO
HandlerInterceptor
声明式事务失效原因
TODO
执行某操作,前50次成功,第51次失败a全部回滚b前50次提交第51次抛异常,ab场景分别如何设置Spring(传播性)
- 全部回滚:@Required
- 只会第51次:REQUIRES_NEW
最大程度的模拟并行Spring的事务传播行为
TODO
Async异步调用方法
- 启动类加上@EnableSync注解后,直接在需要的方法上打上@Async注解
- 建议配置额外线程池使用@Async
- 需注意与其他AOP注入冲突问题,可以用@Lazy注解解决
如何在 Spring Boot 启动的时候运行一些特定的代码?
- 可以实现接口
ApplicationRunner或者CommandLineRunner,这两个接口实现方式一样,它们都只提供了一个run方法 - Spring Listener周期启动?
Spring Boot 有哪几种读取配置的方式?
- Spring Boot 可以通过
@PropertySource,@Value,@Environment, @ConfigurationPropertie注解来绑定变量
bootstrap.properties 和 application.properties 有何异同
- 都可以是核心文件
- bootstrap优先级比application高
- Springboot一般使用application,SpringCloud使用bootstrap
跨域问题
- 后端通过通过实现WebMvcConfifigurer接口然后重写addCorsMappings方法解决
SpringBoot异常处理相关注解?
- @ControllerAdvice
- @ExceptionHandler
SpringBoot配置监控?
- Maven 引入 spring-boot-starter-actuator
相同的服务A、B、C,挂了一个A,RESTAPI怎么知道A挂了并调用 B
TODO
前后端分离的session失效问题,能否用redis 替代session
- Token返回前端,前端Header带token
- 可以
Spring Cloud 相关
为什么要进行系统拆分?如何进行系统拆分?
TODO
什么是微服务?
微服务之间是如何独立通讯的?
- HTTP:OpenFeign
- 二进制:Dubbo
- MQ
微服务架构优缺点
TODO
服务之间如何快速通信
- RESTful API
- MQ
- RPC
- WebSocket
- gRPC
怎么避免微服务深度调用
TODO
OpenFeign底层调用原理
TODO
Ribbon的工作原理
TODO
Sentinel如何实现熔断
TODO
Spring Boot 和 Spring Cloud,谈谈你对它们的理解?
- Spring Boot基于Spring的脚手架
- Spring Cloud是一套依托于Spring生态的微服务解决方案
Sentinel内部是怎么统计 QPS指标达到限流的目的?滑动窗口算法的实现?如何判断请求在哪个时间窗口内?
TODO
如何限流?在工作中是怎么做的?说一下具体的实现?
TODO
集群分布式 Session 如何实现?
- Redis存储,各服务器共享
- tomcat-redis-session-manager,session粘滞:强行分发session到各个服务器
如何设计一个高并发的系统
TODO
请解释一下什么是C10K问题,后来是怎么解决的
- 在同时连接到服务器的客户端数量超过 10000 个的环境中,即便硬件性能足够, 依然无法正常提供服务
- 多路复用,非阻塞IO,减少不必要性能损耗,异步响应
高并发除了加锁还有什么解决方案
TODO
Spring Cloud 和 Dubbo 有哪些区别?
- 定位不同:SpringCloud是解决方案,Dubbo作用于服务调用与治理
- 生态不同:SpringCloud是Spring平台生态,Dubbo初始设计是SOA的RPC远程调用
- 调用方式:SpringCloud是Http调用,通常是Rest风格。Dubbo使用Dubbo协议,接口一般是Java的Service接口,传输二进制数据,内部Netty的NIO方式,性能更好
- Spring Cloud注册中心Eureka(Spring Cloud Alibaba是Nacos),Dubbo采用Zookeeper
Eureka和zookeeper都可以提供服务注册与发现的功能,请说说两个的区别?
TODO
SpringCloud几个组件主要功能
TODO
Stream Binder是什么
TODO
分布式微服务的组件和底层代码(如GateWay、Sentinal)
TODO
分布式session设置
TODO
分布式session一致性
TODO
分布式接口的幂等性设计「不能重复扣款」
TODO
如何实现分布式锁
TODO
设计一个高并发秒杀系统
TODO
亿级流量多级缓存的架构
服务熔断怎么设计
TODO
微服务高可用如何设计,如3台服务器,一台宕机如何防止这种现象
TODO
Zookeeper
Zookeeper有哪些用
TODO
zookeeper保证的CP,如何保障的
TODO
正式服和测试服公用一个zookeeper,怎么解决交叉消费
TODO
Dubbo
Dubbo与Spring Cloud关系
- Dubbo是一款RPC服务开发框架,解决微服务架构下的服务通信与服务治理问题
- Spring Cloud是一套微服务框架,包含服务治理等功能
Dubbo 负载均衡策略都有哪些?
| 算法 | 特性 | 备注 |
|---|---|---|
| Weighted Random LoadBalance | 加权随机 | 默认算法,默认权重相同 |
| RoundRobin LoadBalance | 加权轮询 | 借鉴于 Nginx 的平滑加权轮询算法,默认权重相同, |
| LeastActive LoadBalance | 最少活跃优先 + 加权随机 | 背后是能者多劳的思想 |
| Shortest-Response LoadBalance | 最短响应优先 + 加权随机 | 更加关注响应速度 |
| ConsistentHash LoadBalance | 一致性哈希 | 确定的入参,确定的提供者,适用于有状态请求 |
Dubbo 的工作原理?(带图)
TODO
Dubbo服务发现
TODO
Dubbo 进行服务治理、服务降级、失败重试以及超时重试?
TODO
Dubbo超时内部怎么实现的?如果调用方已经超时产生异常了,提供者执行完毕后还会向调用方写返回值吗
TODO
Dubbo超时重试;Dubbo超时时间设置
TODO
如何保障请求执行顺序
TODO
怎么处理外部调用你们的dubbo 接口超时的情景
TODO
Dubbo中热插拔导致的资源末回收怎么处理
TODO
比如说 SPI创建对象,如果说这个对象中开辟了线程池,那么热插拔的时候,如何来释放这个线程池的资源如何平滑地承接流量,如何真实地load进去呢?怎么实现无感?
说了一个思路,使用钩子函数,开辟守护线程,定期检查是否发生了热插拔替换 如果发生
了就调用这个对象的释放资源的方法
Dubbo 的 SPI 和 Java 的 SPI 有什么区别?
TODO
Dubbo组件之间的关联性
TODO
如何自己设计一个类似 Dubbo 的 RPC 框架?
TODO
gRpc
gRpc是什么,有什么优点
TODO
gRpc和Rest区别是什么
TODO
gRPC用的是什么协议
TODO
gRPC为什么使用protoBuf作为序列化机制,跟其他二进制有比有什么优势
TODO
注意阿里hessian
gRPC流程是什么
TODO
gRPC支持哪些类型的序列化
TODO
分布式事务
分布式事务,缓存和数据库的一致性保持
TODO
分布式事务如何实现事务Linerizebility?有哪些典型方法,各自有什么优势
- 2PC 3PC TCC Saga事务 本地消息表,MQ消息事务最大努力通知
Seata配置方式
TODO
引入包,相关参数
Seata模式
TODO
TA,2PC,3PC,Saga关联
Seata流程
TODO
Seata AT模式两阶段过程
第一阶段:开启全局事务,注册分支事务,存储全局锁、业务数据与回滚日志
第二阶段:事务协调者根据所有分支状况,决定当前事务是commit还是rollback。
两种结果都需删除undolog日志、全局事务、分支事务、存储的全局锁。
分布式事务与分布式锁(扣款不要出现负数)
TODO
Nacos
Nacos作用
TODO
Nacos优缺点
TODO
Nacos 1.x版本作为注册中心原理
- Client端Http向Nacos Server发送注册请求
- Client端向Nacos Server查询服务提供方注册的列表数据
- 每10s定时拉取 + 检测到服务提供者异常,基于UDP协议推送更新
- 服务Client每5s定时心跳推送给Nacos Server,检测服务状态
- Nacos Server定时心跳任务检查
- 集群同步任务使用Distro
Nacos注册中心是 AP还是CP
TODO
Nacos和Erueka区别
TODO
Nacos和Zookeeper区别
TODO
Nacos和Apollo区别
领域
Nacos主要关注微服务场景下的服务发现、配置管理和DNS解析。
Apollo主要关注企业级应用场景下的配置管理
协议
Nacos支持Restful和gRpc协议,Apollo只支持Http协议
数据存储
Nacos 使用MySQL存储,Apollo使用自带H2数据库存储
功能特性
Nacos提供服务注册和服务发现、动态配置、服务健康检测、流量管理等功能。
Apollo提供分布式配置管理、灰度发布、发布审计等功能。
社区生态
Nacos有国内社区生态,Apollo国际生态广
一个Nacos如何进行不同环境隔离?如果是在一个nameSpace下又如何隔离?开发环境下,前端怎么调用指定的后端
TODO
Nacos和euraka的区别
TODO
MQ 相关
通用问题
MQ选型
- Kafka:高吞吐量,适合数据量大的业务
- RocketMQ:拥有事务消息,可靠性要求高可使用
- RabbitMQ:结合Erlang并发性好,但不利于二次开发
- ActiveMQ:维护越来越少,不建议使用
如果让你写一个消息队列,该如何进行架构设计?说一下你的思路
TODO
手写生产者消费者(Product A、C,Follower B、D,Bind AC && BD + Exchange)
TODO
项目上用过消息队列吗?用过哪些?当初选型基于什么考虑的呢?
TODO
MQ部署是单机还是集群呢?你们高可用是怎么保证的呢?
TODO
MQ有遇到过重复消费的问题吗?怎么解决的呢?
- Redisson+幂等性判断
MQ有遇到过消息丢失吗?可靠性怎么保证呢?
TODO
如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?
TODO
如何保证消息的一致性
TODO
Kafka相关
Kafka特性
- 高吞吐量
- 扩展性强
- 多客户端支持
- Kafka Stream流处理
- 消息压缩
- 消息持久化
Kafka可以不用zookeeper吗
- 历史版本不可以
- 新版本2.8后可以使用KRaft脱离zookeeper
Kafka 的 partition和 block
TODO
Kafka底层原理
TODO
Kafka机制
TODO
Kafka事务
TODO
如何处理消息堆积
TODO
如何高并发顺序消费Kafka中的数据
TODO
Kafka消息顺序性
TODO
Kafka如何管理偏移量的
TODO
Kafka持久化内存满了除了迁移还能怎么办
TODO
零拷贝
TODO
mmap和sendFile区别
TODO
Kafka的索引使用的是什么数据结构
- LSM树
Kafka消费过程时,PageCache污染原因
TODO
如何理解Kafka的端到端延时
Producer
- linger.ms 设定ms时间内发送一批消息
- batch.size 设定积攒多少条消息进行发送
- compression.type 压缩打包到消息,减少带宽耗费时间
- max.inflight.requests.per.connection Broker 响应时间
Broker
- acks = 0 在Produce发送后即可,不需要等待Broker反馈
- acks = 1 需记录到Broker PageCache 才响应Producer
- acks = -1 必须在所有副本都被同步后才能响应Producer
Consumer
fetch.min.bytes = 1
fetch.max.wait.ms = 500
设定一次拉取多少条消息,如果攒不够就在指定等待时间内拉取下一批次消息
Kafka数据丢失解决方法
Producer
- 设置 acks = all 等待broker将数据完整写入副本响应后,认为数据发送成功
- 设置retries = 10 重试次数
Broker
多目录参数设置
log.dirs
强制刷盘设置(不建议)
log.flush.interval.messages
log.flush.interval.ms
log.flush.scheduler.interval.ms
Consumer
- ack 应答机制
Kafka如何保证消息有序
每个Topic只设置一个Partition,保证写入有序,但不保证网络问题导致的顺序变更
局部有序
同类型消息放入Topic的同一分区
Kafka顺序读为什么快
- PageCache对Block file中数据的预读
Kafka顺序写为什么快
- 物理地址和逻辑地址保证一致,减少磁盘旋转寻址开销,直接追加写
Kafka从设计上怎么保证吞吐量
TODO
RocketMQ相关
RocketMQ如何保证消息不丢失
TODO
生生产者产生消息;
消息发送到存储端,保存下来
消息推送到消费者,消费者消费完,ack应答
RocketMQ支持哪些消息类型
TODO
RocketMQ的Consumer用的什么模式
TODO
RocketMQ事务消息是否了解?场景题:比如下单清空购物车,你是如何设计的
TODO
事务消息主要用来解决消息生产者和消息消费者的数据一致性问题。
RocketMQ为什么不用Zookeeper作为注册中心
TODO
RocketMQ保证顺序消费,为何要在Broker端锁定该消息队列,保证只有一个消费者会获得该消费队列
- rocketMQ再均衡没有类似kafka的coordinator参与,都是各个consumer独立完成。肯存在某一时刻多个consumer消费同一个consumequeue的情况
RocketMQ如果消费者组A下面有两个消费组A1,A2,问消费者A1和A2是否消费不同的主题
TODO
RocketMQ如何保证事务
TODO
RabbitMQ相关
RabbitMQ 如何保证不丢消息
主要方法
持久化消息,Consumer ACK机制
其他方法
备份队列,镜像队列和生产者确认机制
RabbitMQ交换机有哪些
TODO
RabbitMQ如何顺序消费
- MQ的队列是有序的,但是消费组可能速度不同,需要只留一个消费者。如果需要绝对顺序,则不可开启普通线程池避免消费时乱序
Cache 相关
Redis
Redis 的String 是如何实现的
TODO
Redis GEOSEARCH数据结构怎样的,底层实现
TODO
Set底层结构是什? hyperloglogs了解吗?
TODO
Redis Hash与Java HashMap区别
TODO
Redis主从、哨兵和集群区别
主从
主从复制,读写分离。但不能自动恢复
哨兵
哨兵选举可以自动恢复,着眼于高可用。但不能解决负载均衡问题
集群
着眼于高并发,可以解决负载均衡问题,方案是slot,通过一致性哈希算法将数据分散在不同的slot中 16384个slot
Redis事务
- 事务是一个单独的隔离操作:事务中所有命令都序列化、顺序执行。执行过程中不会被其他命令打断
- 事务是一个原子操作:要么全部执行,要么全部不执行
- MULTI、EXEC、DISCARD、WATCH
Redis为什么是原子性的
单线程操作数据
Redis 提供事务支持,允许将多个命令作为单个原子操作执行。
Redis 事务使用 MULTI 和 EXEC 命令将命令组合在一起并将它们作为单个事务执行。如果事务中的任何命令失败,则回滚整个事务,确保整个事务的原子性。
Redis为什么快
- 内存存储
- IO多路调用epoll网络模型
- 单线程查询数据,减少切换CPU分片耗时
- 数据结构优化
Redis底层实现
TODO
Redis如何更新缓存
TODO
Redis如何内存优化
- 尽可能使用Hashes,它使用内存非常小
Redis数据一致性怎么做的
TODO
Redis Hashtable 如何扩容的
TODO
为什么要设计Redis Slot结构,如何查找数据
TODO
Redis的哈希槽算法和哈希一致性算法
TODO
Redis rehash过程中,旧hash数据被访问后会把该数据Copy到新表,这个过程是以单条数据为粒度还是以桶为粒度拷贝的
- 以桶为单位
- 即使桶数据很大,它也是以默认10个key为单位复制,避免其他指令阻塞。
- 可以通过
hash-max-ziplist-entries和hash-max-ziplist-value命令更改批次量
如何找出Redis中的慢查询记录
- redis设置slowlog-log-slower-than、 slowlog-max-len两个参数
- slowlog get 查看
- redis慢日志的删除采用 先进先出 的方式
Redis List过大如何优化
- 分片
你们是如何对Redis进行性能优化的
- Key尽量短
- 数据尽量小
- 不使用lrange之类命令查询
- 设置Key生命周期
- 选择默认LRU策略
为什么 使用 Redis 而不是用 Memcached
- Redis可以持久化数据
- 速度更快
- 支持数据结构更多,Memcached只支持字符串,Redis支持String,Hash,List,Set,ZSet,以及BitMap、Geospatial、Hyperloglog
Redis的Set底层什么时候是Hash什么时候是跳表
TODO
ZSet数据结构以及空间复杂度
TODO
跳跃列表原理怎么实现
TODO
quickList和zipList原理
TODO
zipList时间复杂度
TODO
Redis怎么做限流
TODO
redis 的zset 滑动窗口限流,顺便说了一下漏桶和令牌桶
Redis异步消息怎么处理
TODO
Redis 5.0 新增Stream对它有什么理解
TODO
为什么redis7用listpack取代ziplist
TODO
大批量删除Redis key导致Redis不稳定如何解决
- 开启 lazy-free
- lazyfree-lazy-eviction:当 redis 内存达到阈值 maxmemory 时,将执行内存淘汰
- lazyfree-lazy-expire:当设置了过期 key 的过期时间到了,将删除 key
- lazyfree-lazy-server-del:这种主要用户提交 del 删除指令
- replica-lazy-flush:主要用于复制过程中,全量同步的场景,从节点需要删除整个 db
如何保证Redis高并发、高可用
- 集群Slot
Redis持久化机制,以及优缺点
RDB 快照方式半持久化记录,循环时间点替换临时文件
优点
只有一个dump.rdf方便持久化
容灾性好,一个文件可以保持到安全的磁盘
性能最大化,fork子进程完成写操作,让主进程持续处理命令,IO最大化
数据集大时,比AOF启动效率高
缺点
数据安全性低,如果发生一次故障丢失临时文件,则全部丢失
AOF 所有命令行记录以redis命令请求协议歌手完全存储
优点
数据安全,aways/seconds/times
append追加写入,宕机可以少丢数据,且可以提高redis-check-aof工具解决数据一致性问题
rewrite模式,可以优化合并指令
缺点
AOF文件比RDB大,且恢复速度慢
数据集大时,比RDB启动效率低
AOF的文件特别大的时候有什么解决办法
TODO
Redis回收进程如何工作
- 每次添加信数据时允许,检查maxmemory限制,大于则根据测量回收
雪崩、穿透、击穿问题怎么解决
- 雪崩,不同过期时间
- 穿透,即查询不存在数据。无数据时设定假数据,有时进行更新
- 击穿,互斥锁
Bloom过滤器原理
TODO
Redis的内存用完了会发生什么
- 新增报错,但旧数据可查询
- 等待Key过期与LRU删除
在项目里面缓存是怎么用的
- 修改频次低的数据缓存到Redis进行快速查询反馈,权限模块功能权限的缓存
- 队列使用,redission.getBlockingQueue(queueName),多节点消费使用同一中间件新增List数据判定是否全部处理,出库模块
- redission锁,高并发修改数据时进行锁定
用Redis实现一个成绩的排序
- Sorted Set
Redis 大key删除时容易把redis 搞崩,怎么解决
TODO
高并发下,redis和mysql双写一致性如何保证
- 旁路缓存读写模式
Redis Cluster,在Master节点执行命令返回后,向节点同步之前Master挂了,子节点升级后数据如何保证一致
TODO
Redis 存在线程安全问题吗
- 不存在,主线程处理数据,其他线程处理网络IO
Redis主从复制原理
TODO
答:Redis 可以使用主从同步,从从同步。第一次同步时,主节点做一次 bgsave,并同时将后续修改操作记录到内存 buffer,待完成后将 rdb 文件全量同步到复制节点,复制节点接受完成后将 rdb 镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
一个字符串类型的值能存储最大容量是多少
- 512M
PipeLine好处
- 将多次IO往返时间缩减为一次,前提是pipeline执行的指令直接没有因果关系性
Redis 大量Key集中过期,为什么这时访问Redis其他Key有延迟
- 单线程问题导致。Redis必须在数据过期清理任务结束后才能响应后续访问任务,因此会导致访问延迟
- 过期策略
- 主动过期:LRU删除,每100ms挑20个Key,如果过期比例超25%则循环删除直至比例低于25%或当前任务时间时间超过25ms才退出循环
- 懒惰过期:访问到Key时如果过期则删除
系统在10:05 设置一个值,并给出5分钟的过期时间,系统刚刚set完之后redis集群崩溃,10:11分系统重启成功,那么redis中set的值是否还存在
未开启备份状态下,或落盘处于时间差,则不存在
开启备份状态且成功状态下
AOF
当Key过期时,追加del key语句,由于从宕机中恢复,没有追加语句,Key会存在
主启动:存在,但LRU或惰性删除,当第一次访问时删除并返回nil
从启动:根据Master当前状态删除,如果访问到slave节点,会获取过期数据
RDB
主启动,忽略已过期的Key
从启动,不忽略,但是LRU惰性删除
MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据
Redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
Redis Cluster数据库
- 无法选择,默认0数据库
基于 Redis 的分布式锁会有什么问题
TODO
主从模型下同步不保证一致会导致锁失效
Redis 分布式锁超时可以超时时间设长一点可以吗?不可以的话需要怎么解决?
TODO
Redis 锁续期这个怎么实现
TODO
在主从模式和 Redis Cluster 中分布式锁会有什么问题
TODO
Redission
Redis Hash Slot概念
- Redis Cluster没有使用一致性hash,而是引入Hash Slot概念,共16384个槽,每个Key提高CRC16校验后对16384取模决定放在哪个Slot
Redis 分布式锁怎么实现的
- SETNX
- RedLock
Redis 分布式锁和 zookeeper 分布式锁区别
- CA
- CP
RedLock红锁算法
- N/2+1
Redission细节源码
TODO
分布式锁超时问题怎么解决
- Watchdog
DataBase相关
如何设计数据库
TODO
基础概念
OLTP与OLAP联系与区别
TODO
索引优化如何实现
TODO
主键是什么,有什么特性
TODO
MyBatis相关
MyBatis传参方式、动态标签
TODO
MyBatis缓存
区分一级缓存和二级缓存
一级缓存
强制开启,同一事务同一语句优先命中一级缓存。
执行参数通过算法生成Cache-Key,结果为Value,存储结构为Map
任何Update、Insert、Delete语句都会清除缓存
二级缓存
非强制开启,外部存储介质,以不同NameSpace隔离。
多Instance状态下,应用A更改 NameSpace-A缓存,不会变更NameSpace-B缓存,当应用B访问会获得错误结果
不建议开启
MyBatis mapper方法名可以一样吗
- 可以,使用的是全限定名称
MyBatis配置文件
TODO
MyBatis比JDBC有什么优势
- 减少JDBC冗余代码,由MyBatis管理开关连接
- 不可以在XML编写SQL,改变SQL不需重新编译
MyBatis如何映射
TODO
MyBatis的运行流程
TODO
MyBatis原理
TODO
MyBatis如何分页
TODO
MyBatis如何解决SQL注入问题
- #占位符
- PreparedStatement预编译
什么是数据库连接池,为什么要连接池
TODO
MyBatis 和hibernate的区别
TODO
数据字典是什么
TODO
MyBatis出现连接超时如何排查
TODO
MyBatis默认连接数是多少
TODO
MySQL
IP地址如何在数据库中存储
32位UNSIGNED INT类型存储
节省空间,不管是数据存储空间,还是索引存储空间
便于使用范围查询(BETWEEN…AND),且效率更高
Java代码中的 移位操作 和 & 计算
MYSQL 命令 inet_aton() 命令将IP字符串转化为数字类型,inet_ntoa 命令将数字转化为字符串IP
MySQL中#和$是什么区别
#是占位符,传入数据会加入””
$是拼接符,不处理传入数据,可能会数据注入
建议使用#
MySQL中char和varchar的区别
- char固定长度255,varchar可变长度65535,理论查询效率char更高,但尾部空格插入时丢弃,不足长度会补齐,建议不变长度字段使用
- InnoDB建议varchar,所有数据都适用指向数据列的头指针
普通索引和唯一索引的效率比较
- 查询:唯一索引比普通索引快
- 唯一索引只有一条,找到所属页二分法查询到第一条即结束
- 普通索引有多条,会一直向下查询
- 写入:普通索引比唯一索引快
- 唯一索引需验证唯一性,因此需要先进行数据查询才可写入
- change buffer缓存的是非唯一索引数据,对于唯一索引内容必须需要磁盘IO检查数据唯唯一性
深度很高的树结构如何存入数据库
TODO
一个大型表如何移动到另一个表上
TODO
SQL查询突然变慢如何分析
- DB CPU是否高峰期
- 慢SQL查询,processlist
为什么不推荐SLECT * FROM
- 字段多
- 执行期优化,全表扫描
SQL如何有效使用复合索引
- 最左匹配
Exist和in的区别
TODO
主键索引唯一索引区别
- Primary Key唯一,Not Null
- Unique 针对字段,可以为Null
千万DB数据分页怎么处理
- 主键处理,记录上一次最大/最小主键,
Where id > primary key value
怎样防止SQL注入
- # 占位符
- 手动处理
SQL查询的索引覆盖
- 二级索引,包含所有需要字段,不回表直接返回
数据库索引的实现,为什么选择这个实现
TODO
索引底层原理
TODO
MySQL索引数据结构,B-TREE与二叉树对比
- B+Tree
- B-Tree指针数据都在一起,B+Tree非叶子节点存储指针和Primary Key,叶子节点存储数据
- 二叉树层数高,且可能形成链表
创建索引的原则
- 唯一索引保证数据唯一
- 为业务常用字段建立索引
- 尽量使用数据内容少的字段作索引
- 索引尽量5个以内
- 删除不再使用的索引
表设计原则
- 符合三大范式
- 减少使用大量空间
- 避免冗余数据
- 使用所以
- 避免联合查询
- 使用合适数据类型
- 考虑并发控制
- 考虑数据访问方式
- 考虑数据安全性
联合索引什么时候使用
- 同时查询多个列
- 高并发的表,曾经联合索引可以减少锁冲突,提高效率
- 范围查询,如果联合索引第一列被用于筛选数据,则会利用索引提高效率
不一定比单列更快,不应该包含过多的列,顺序很重要
SQL语句执行关键字顺序
- SELECT:查询需要返回的列。
- FROM:指定数据表,视图或子查询。
- WHERE:指定查询条件。
- GROUP BY:按照指定列对结果集进行分组。
- HAVING:对分组后的结果进行条件过滤。
- ORDER BY:对查询结果进行排序。
- LIMIT:限制结果集的返回数量。
MySQL的最左匹配原则是利用了B+树的什么特性
TODO
JOIN的实现原理
TODO
MySQL体系结构
TODO
MySQL 范围查询原理
- 聚簇索引,主键指针从左到右
MySQL存储引擎?MyISAM与InnoDB区别?
- InnoDB
- MyISAM 表锁,查询快,指针数据分离
- InnoDB 行锁 B+ Tree,事务,指针数据聚合
只用主键ID查找时 B+Tree和B-Tree哪个快
- B+Tree与B-Tree都是树结构,都只需要进行节点的查找和比较操作,查询速度较为接近
- 但是B+Tree叶子节点更稠密,因此B+Tree可能更快
B+Tree树节点具体存什么
TODO
B+树是数据的顺序一定是从左到右递增的么
TODO
页分裂伪代码,B+树的倒数底层层可以页分裂么
TODO
MySQL一页最大存多少数据
- 16K
B+树3层的话可以存放多少量级的数据
TODO
如何优化MySQL的页分裂算法
TODO
Mysql中InnoDB中的索引有什么特点
https://zhuanlan.zhihu.com/p/366972218
TODO
InnoDB二次写是什么
TODO
Mysql中聚簇索引和非聚簇索引的区别
聚簇索引
叶子节点:包含主键、完整数据、数据页指针。
完整数据用于Cover Index查询,其他查询均向Data Block 数据页指针进一步查询数据再返回。原因是MySQL多个引擎,为了保证通用。
非叶子节点:包含主键、数据页指针,用于Range Query
非聚簇索引
二级索引,叶子节点为索引值和对应的主键,非叶子节点为索引值对应的下一节点的指针。非叶子节点需要一直向叶子节点寻找直至找到主键,再在聚簇索引叶子节点获取数据页指针,进行回表查询。
MySQL索引是作用于库还是作用于表
- 在 MySQL 中,索引是在表上创建的,但它存储在称为索引树的单独数据结构中,该数据结构由数据库引擎管理。所以,你可以说索引作用于表,但它不是表本身的一部分。
- 当执行涉及带有索引的表的查询时,数据库引擎使用索引来更快地定位数据。这可以显着加快查询性能,尤其是对于大型表。
- 所以,综上所述,索引在MySQL中是在一张表上创建的,但是是由数据库引擎单独存储和管理的。
建立联合索引的时候要注意什么
- 最左匹配
- 数据量小
- 限制字段数目
索引下推是什么
TODO
MySQL执行语句流程
- 连接器
- 解析:解析 SQL 查询以检查其语法并确保查询中引用的表和列存在。
- 缓存:如果之前执行过查询,MySQL 可能会从其查询缓存中检索查询结果,而不是再次执行查询。
- 优化:查询优化器确定查询的最佳执行计划。它考虑各种因素,如可用索引、表大小和查询类型来优化查询执行计划。
- 执行:执行优化查询,包括从表中读取数据、应用过滤器和排序以及根据需要连接表。
- 结果检索:结果集被发送回客户端应用程序,然后客户端应用程序可以处理结果。
数据库设计三大范式?开发中应该遵守吗?
- 第一范式:数据库表的每一列都是不可分割的基本数据项
- 第二范式:确保表中的每列都和主键相关【符合1NF,同时非主属性完全依赖于主键】一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
- 第三范式:确保每列都和主键列直接相关,而不是间接相关【符合2NF,并且消除传递依赖】主键关联,没有其他数据相同,减少冗余
- 尽量满足,空间换时间(JSON查询等)
MySQL乐观锁悲观锁实现
- 乐观锁
- 悲观锁
MySQL表锁、页面锁、行锁的作用及优缺点?
TODO
MySQL 5.6.17后加索引时会锁表吗
TODO
MySQL为什么添加索引或字段时会造成锁表
TODO
MySQL行锁怎么实现的
TODO
MySQL 行锁和表锁 互斥吗
TODO
MySQL读写锁
TODO
MySQL?什么时候会触发排它锁?
TODO
MySQL间隙锁是什么
TODO
数据库什么时候会锁行
更新、删除
保证不好有其他会话操作,避免数据出现一致性问题
插入
如果有Primary Key或者Unique Index,会锁定确保其他会话不好插入重复数据
事务
执行事务语句时,会锁涉及到的所有行,确保一致性和完整性
在数据库中,行级锁是最小的锁粒度。如果同时有多个会话需要访问同一个行,那么其中一个会话会获得锁,而其他会话需要等待锁被释放才能访问该行。在高并发的情况下,如果锁的粒度过大,会导致大量的等待,从而影响数据库的性能。因此,在设计数据库时需要考虑好锁的粒度,以确保系统的高并发能力。
MySQL死锁的解决办法
TODO
MySQL中distinct和group by性能比较
TODO
临键锁只与非唯一索引有关吗?那对主键id做范围查询的时候加的什么锁?比如id >7 for update
TODO
你知道MySQL中redo log、binlog、undo log 区别与作用?
- binlog 数据恢复与备份,二进制
- redo log 持久化数据,磁盘文件,宕机恢复
- undo log 事务恢复数据,原子性与一致性,通过MVCC保证隔离型。Insert语句执行成功后删除,update语句保留
SQL优化有哪些着手点
- 慢查询日志,Explain,业务常用Key索引
索引失效场景
TODO
千万数据量的表每日ETL定时同步,如何优化查询
TODO
什么是数据库事务
TODO
脏读,不可重复读和幻读主要有什么区别
脏读
读到未提交的事务数据
不可重复读
当前事务中读同一条数据内容不一致
幻读
当前事务中,同一条查询语句获得结果数量不一致
MySQL中的GTID是什么
- GTID 代表全局事务 ID。在 MySQL 中,GTID 是在数据库服务器上执行的每个事务的唯一标识符。
- GTID 是两部分的组合:执行事务的服务器的唯一服务器 ID,以及为该服务器上的每个事务递增的序列号。
- 用处
- 轻松跟踪复制进度,确保所有服务器都是最新的。
- 简化的故障转移:如果服务器发生故障,您可以使用 GTID 确定在该服务器上提交了哪些事务,然后在新服务器联机时将这些事务应用到它。
- 更轻松的架构更改:使用 GTID,您可以在主服务器上执行架构更改,并将这些更改自动复制到所有辅助服务器,而无需担心冲突或丢失事务。
GTID可以全局事务,为什么还需Seata
- 微服务如果所有应用都在同一个DB,可以通过GTID进行全局事务管理
- 但是微服务一般有多个数据库,跨数据库之间全局事务需要额外Middleware或TCC技术
说说你了解的数据库的隔离级别、MVCC
| 隔离级别 | 问题 | MVCC作用 |
|---|---|---|
| 读未提交 | 脏读、不可重复度、幻读 | 不处理,直接最新数据 |
| 读已提交 | 不可重复读,幻读 | 快照读:每个数据读取前都生成一个快照 |
| 可重复度 | 幻读 | 快照读:启动事务时生成快照,事务期间都使用该快照 |
| 序列化 | 加锁串行化访问,不需MVCC处理 |
如何实现 MySQL 的读写分离?MySQL 主从复制原理是啥?如何解决 MySQL 主从同步
TODO
为什么要设计事务隔离级别
- 解决并发问题
Text/Blod如何索引
- 存储过程促发器
MySQL复制有几种方式
基于语句的复制(Statement-based Replication,SBR)
将Master DB的SQL执行语句复制,在Slave DB执行相同SQL语句
易于理解和调试,但是可能由于数据库版本差异导致失败
基于行的复制(Row-based Replication,RBR)
将Master DB上修改的行记录,并在Slave DB将相同的行进行插入或修改实现数据复制
可避免版本导致的语法差异,但需更大磁盘空间和带宽
混合复制(Mixed-based Replication,MBR)
将基于语句和行复制结合,根据情况自动选择使用哪种复制
半同步复制(Semi-synchronous Replication)
在数据库上执行写操作时,至少等待一个从数据库将数据同步过去并确认,才算写操作成功,可提高数据一致性和可用性,但增加IO和网络开销
组复制(Group Replication)
允许多个MySQL实例作为一组,在组内进行数据同步和决策,提高可用性和容错性。组内实例提高复制日志和心跳信息进行通信,并根据投票选举保证数据一致性和高可用性
MySQL主从延迟如何解决
TODO
如何设计表和表结构
TODO
有一个商品表,有不同商品,对应不同供应商,可能还有价格降价活动,如何设计表
数据量很大的情況下,需要先从db中查询用户基础信息然后根据用户基本信息去查询redis中关联的用户关联信息,这里忽略OOM的情况下 ,有什么办法去提升性能呢
TODO
一个文章表 宇段包含 文章类型 发布时间 ,查询个发布时间段内特定文章类型文章 如何建立索引(联合索引(文章类型,发布时间))
TODO
limit 1000000 加载很慢的话,你是怎么解决的呢
- 连续ID使用 where id > x 偏移量再向下limit,但是跳页有问题
- orderby + 索引
- 利用延迟关联或子查询优化
Select for update作用
- 悲观锁查询
- 查询不带索引/主键是表锁
- 带索引/主键是行锁
现行的基于locality 的页缓存有什么不足?
TODO
如何结合查询器/ 优化器来优化缓存配置
TODO
数据库表达式计划缓存说下。表达式计划缓存select怎么生成的
TODO
union all 在MvSQL5.7里改进了哪些?
TODO
一千多万的表A 和两千万的表b,要求把b有a没有的插入,同时把a数据和b有差异的筛选出来。有什么个方案?
- Right Join On 左表关键字 = null
迁移过程中双读双写具体是什么样的方案
TODO
双写过程中只写成功了其中一个 DB,返回给用户报错,那是否会存在脏数据
TODO
双读具体是什么方案,其中一个读成功了就返回还是要两个都读成功才可以
TODO
数据宕机如何解决
运维侧
设备宕机无响应
主从切换/灾备环境切换。宕机期间的数据根据redolog恢复
设备未宕机但响应慢
临时增大最大连接数
开发测
新模块新功能异常导致的DB宕机
回滚旧版本
根据日志查看是否由于慢查询多导致响应异常
待业务过高峰期进行SQL语句
MySQL ISAM InnoDB,增长主键,当突然断电停机后进行重启,两个引擎中的自增主键会连续吗
存储过程
TODO
Oracle
Oracle临时表有哪些
TODO
分布式 && 拆表
分库分表方案
TODO
- 水平分库:以字段为依据,按照一定策略(hash、range 等),将一个库中的数据拆分到多个库中。
- 水平分表:以字段为依据,按照一定策略(hash、range 等),将一个表中的数据拆分到多个表中。
- 垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
- 垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
分库分表可能遇到的问题
TODO
- 事务问题:需要用分布式事务啦
- 跨节点 Join 的问题:解决这一问题可以分两次查询实现
- 跨节点的 count,order by,group by 以及聚合函数问题:分别在各个节点上得到结果后在应用程序端进行合并。
- 数据迁移,容量规划,扩容等问题
- ID 问题:数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑 UUID
- 跨分片的排序分页问题(后台加大 pagesize 处理)
旧服务单表,如何改造新服务多表,且新旧服务同时运行
TODO
分表分错了后如何排查
TODO
如何拆表,优缺点
TODO
我们为什么要做分库分表(业务侧)我们为什么要做分库分表(数据侧)
TODO
分库分表之后,id 主键如何处理?
- 继续使用原主键简单场景,设置步长
- 低频场景,UUID
- 高频场景,雪花算法
表拆分后如何查询
TODO
为什么分布式不推荐JOIN
TODO
TiDB
TODO
ElasticSearch相关
ES倒排表压缩算法
TODO
FOR
ES 索引过程
TODO
如何瞬间完成海量数据检索
- ES,倒排索引
ES如何加快分词搜索速度,倒排索引原理
TODO
ES脑裂问题
TODO
调优
TODO
ES模糊查询要怎么写
- fuzzy
Click House
TODO
Network相关
OSI七层模型,每层作用
TODO
网络层的主要功能(路由),运输层TCP的主要核心(可靠传输);数据链路层最核心参数(MAC,面试官说不对,应该是调整包大小的参数
TCP如何实现可靠连接
TODO
TCP的拥塞机制
TODO
TCP在网络中的第几层
- 第三层
TCP长连接的应用
TODO
TCP协议头多少字节
- 60
TCP三次握手四次挥手
TODO
TCP四次挥手,挥手从服务端发起会怎么样
TODO
FIN-WAIT-2是什么时候的
TODO
TCP 粘包怎么解决
TODO
TCP滑动窗口为0的情况什么时候出现,如何解决
TODO
TCP如何保证传输过程的正确性
TODO
TCP UDP区别
TODO
列举几个网络通信协议
TODO
HTTP请求类型
- OPTIONS:返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送’*’的请求来测试服务器的功能性。
- HEAD:向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。
- GET:向特定的资源发出请求。
- POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。
- PUT:向指定资源位置上传其最新内容。
- DELETE:请求服务器删除 Request-URI 所标识的资源。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
- CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
HTTP和TCP的关联
TODO
HTTP和HTTPS的主要区别
- HTTP明文传输
- HTTPS 使用TLS (SSL) 来加密普通的HTTP 请求和响应,并对这些请求和响应进行数字签名
HTTPS交互过程
TODO
HTTPS 原理,怎么实现 HTTPS这个协议
TODO
什么是TLS
TODO
网络收到很多的TIME_WAIT状态包,原因以及解决方案
原因
主动关闭TCP一方发送最后一个ACK后等待对方回应FIN,一般最长等待2MSL。
如果不等待,接收方可能因网络原因延迟,导致重传FIN包。
如果直接关闭,可能导致接收方获取延迟的ACK包后,旧TCP连接丢失,只能返回RST包。新TCP连接建立后,延迟包可能干扰新连接
解决方案
服务器tcp_tw_recycle设置为1
服务端出现大量CLOSE_WAIT原因及解决方案
原因
被建立连接服务器没有进行第三次挥手。
网络连接未释放,通常是服务端发生异常后未关闭或者服务器参数配置时间过长。即服务端耗时超时,客户端发起FIN请求,服务器回应ACK,此时服务器端就是CLOSE_WAITss
MySQL可能存在事务没有正确commit或rollback可能
解决方案
JAVA开发查看应用ThreadDump,查看大量线程在哪里Blocked
网络IO的五种模型
TODO
RPC HTTP区别?
- 不是相同类型,HTTP是通用协议,RPC是远程调用思想,主要是对底层协议封装
- RPC内部实现可以多种协议进行(如TCP、DUBBO),HTTP某种意义上也是RPC调用。自定义的RPC可以更高效
输入一个URL会发生什么
TODO
首先DNS解析
面试宫:为什么要解析 URL
我:http协议的三次握手.
面试宫:2次握手行不行
我:从缓存里面拿资源..
面试官:知道什么是启发式缓存吗,在什么条件
下触发
首先做的是判断输入的值是否符合域名或者服务器地址规范。不符合是调用内置搜
索引擎搜索,符合的话先查缓存,没缓存才开始dns解析,3次握手核心是确保客户端,服务端的发送及接受能力,启发式缓存是当我们完全没去设置缓存机制的时候,浏览器会因为内核不同有一套自己的启发式缓存,类似强缓存
IO多路复用是否是异步
- 处理IO时,不论是否阻塞都是同步IO
- epoll内部每个通知等待都是异步的,都是对外部而言是同步的,底层使用epoll的框架后,可以做成异步的,只需暴露给外部的接口无需等待返回值即可
- https://www.zhihu.com/question/59975081
- https://www.zhihu.com/question/19732473
IO多路复用的优缺点
TODO
RTMP是什么
TODO
描述网页一个Http请求,到后端的整个请求过程
TODO
长连接的方式有哪些
TODO
Netty
https://it-blog-cn.com/blogs/interview/netty.html
https://juejin.cn/post/6999225355374428168
Netty的线程模型,零拷贝实现
TODO
Hardware
路由器和交换机的工作原理
TODO
Middleware 相关
Nginx
Nginx负载均衡策略,相关场景
- 轮训
- 权重
- IP hash:hash算法分配
- fair:响应时间分配
- sticky:Cookie/Session识别
Nginx如何识别移动端PC端
- user_agent
Nginx动静分离如何实现
TODO
Nginx做负载均衡,增加work_connections配置横向拓展Nginx实例
TODO
Tomcat
TODO
链路追踪
TODO
大文件怎么读取分割记录并保持顺序
TODO
Tools 相关
分布式锁在项目上的使用
- redission
- 数据库根据数据增删
Theory 相关
CAP定理和BASE理论
CAP
- Consistency 一致性 (节点中所有可用数据)
- 分布式系统下,一致性指的是数据在多个副本中保证一致性
- Availability 可用性 (每个请求都能在有限时间内得到回应)
- 服务需要一直处于可用状态,对于每一个用户操作都能在有限时间内响应结果
- Partition Tolerance 分区容错性 (保证分散的数据之间能够联通)
- 不同分区数据不能因故障无法联通,提高容错性就是增加节点将数据复制到这部分节点上。
- 提高数据节点存在越多,容忍性越高,但要复制的数据就越多,一致性就越难保证。保证一致性需要等待所有节点写入成功,但会带来可用性问题。
- 为了保证一致性,更新数据节点时间就会延长,可用性就会降低。
- 同时只能满足其中两项
- 集群主机分散,节点、网络故障是常态,因此一般需要保证P和A,舍弃C
- Consistency 一致性 (节点中所有可用数据)
BASE
- BA - Basically Available
- 出现不可预知故障时,允许部分节点失效,但要保证整个系统仍处于基本可用状态
- Soft state
- 允许数据在不同副本上有一定延迟同步。mysql replication的异步复制也是一种体现。
- Eventually consistent
- 存储在数据没有新的更新状态下,系统所有副本在到达某个时间节点后,数据达到同步状态。
- 最终一致性是弱一致性的一种特殊情况
- BA - Basically Available
弱一致性与最终一致性区别
弱一致性即使过了不一致时间窗口,后续的读取也不一定能保证一致,而最终一致过了不一致窗口后,后续的读取一定一致,才能说清楚弱一致和最终一致的区别
CAP与BASE关系
- 在分布式的数据系统中,你能保证下面三个要求中的两个:一致性,可用性,以及分区容错性。在此模型上构建的系统将称作 BASE(基本上可用软状态最终一致)架构,不满足 ACID 性质。
ACID
- Automicity 原子性
- 一个事务必须被视为不可被分割的最小工作单元
- Consistency 一致性
- 数据库总是从一个一致性状态切换到另一个一致性状态
- Isolation 隔离性
- 一个事务中对数据的变更在提交之前,对于其他事务是不可见的
- Durablity 持久性
- 一旦提交事务,则所做的修改永久写入磁盘
- 强一致性
- Automicity 原子性
什么是Serverless
- 无状态,即方法执行结束后,不改变类的状态,不变更全局参数
如何向面试官证明你做的系统是高可用的?
- SLA 服务等级协议(Service-Level Agreement,SLA)
- 服务监控措施
- 系统要素指标:主要有 CPU、内存,和磁盘。
- 网络要素指标:主要有带宽、网络 I/O、CDN、DNS、安全策略、和负载策略。
- 监控报警策略
- 系统应用策略
UV/PV
TODO
什么是灰度发布
TODO
解释型语言和编译型语言的区别?除了运行速度别的角度?生产效率
TODO
哈希表为什么查找复杂度是常数
TODO
DDD
设计思想
TODO
核心解决的问题
TODO
分层架构
TODO
优缺点
TODO
Linux
如何查看TCP连接
TODO
Kubernetes
Front-End
JavaScript
Ajax
Layui
jQuery
React
Freemarker
TODO
Angular
Angular介绍下双重绑定的机制
TODO
Other
NIO Channel底层原理
- NIO 通道使用非阻塞 I/O 模型,这意味着它们在等待 I/O 操作完成时不会阻塞线程。
- NIO Channels 使用与 epoll 类似的机制,这使得它们可以使用单个线程有效地处理许多并发连接。
- NIO Channels 使用 mmap 和 scatter-gather copy 等各种技术在用户空间和内核空间之间高效地传输数据,从而减少上下文切换并降低 I/O 成本。
拿到一个需求你会做哪些事情
TODO
估算某城市的便利店数量
- 品牌连锁
- 自营根据人口密度估算
CPU占用突然升高该怎么分析
- 如果是业务量突然增加,考虑扩容问题
- 如果业务量没变,则查看当前运行程序是否有出现死锁等问题,可以打ThreadDump等查看
线程假死怎么排查,如何处理
TODO
对称加密和不对称加密的区别
TODO
常用的高可用方案
TODO
有哪些MHA结构的方案
TODO
怎样表达滑动窗口限流
TODO
查询接口调优,不用缓存且要求实时性,如何调优
- 优化数据库
- 调优数据库查询语句
- 根据需求配置数据库索引
- 使用搜索引擎如ES
服务上下游为什么用sign而不是oauth协议生成key
- 服务器通常使用签名、时间戳和其他消息数据的组合来生成访问密钥,因为它提供了一种简单灵活的方法来保护和验证请求,而没有完整 OAuth 协议的开销和复杂性。
- OAuth 是一种用于授权和身份验证的标准化协议,它提供了一种安全且标准化的方式来代表用户访问受保护的资源。但是,OAuth 被设计为可在许多不同场景中使用的通用协议,这意味着针对特定用例的实施和配置可能很复杂。
- 相比之下,使用签名、时间戳和其他消息数据的组合来生成访问密钥是一种更简单、更灵活的方法,可以根据应用程序的特定需求进行定制。通过基于消息数据和只有服务器知道的密钥的组合生成访问密钥,服务器可以确保请求经过身份验证和授权。此外,通过在访问密钥中包含时间戳,服务器可以防止重放攻击,攻击者在这种攻击中拦截并在以后重放有效请求。
- 总的来说,虽然 OAuth 可以成为保护和验证请求的强大工具,但对于一些更简单、更灵活的方法就足够的场景来说,它复杂程度过高了。
操作系统的悲观锁、乐观锁
TODO
如何实现高可用,项目如何实现高可用的
TODO
如何单元测试,覆盖率如何
- Junit
- JaCoco
MapReduce原理
TODO
怎么解决高并发下流量
TODO
核心线程20,最大600,阻塞队列200,当QPS 200时,请求调用第三方(是一个长时间阻塞任务),不加机器情况下,如何提高吞吐量
TODO
查询接口,不使用缓存且要求实时性,如何调优
TODO
用户查询一张表,流量控制降级时,如何兜底
TODO
用户订单按什么自动分表,分表后如何按照时间段查询指定时间段内所有用户订单
TODO
Channel的底层原理
TODO
环形缓存+双队列
channel 和 select的一小段代码,让说出打印内容
上下文切换content,我只说了下withtimeout超时时,使用,或者记录一些kv值,供后面的方法使用
TODO
如果你来设计一个类似淘宝的系统,你怎么划分微服务?
TODO
如果有一个人他伪造了很多合法的QQ号并且多台主机来攻击怎么办
TODO
连接相同的基站,网络出口可能是相同的,锁定IP误伤怎么办
TODO
超卖问题
TODO
9个盒子1个有90克 剩下的100克 最少能用几次称出90克的
TODO
常见的索引结构
哈希表,有序数组和N叉树
系统大量用户登录时出现session连接过多导致用户被登出,如何解决
TODO
接口幂等是如何保证的
TODO
实现幂等一般有这8种方案:selecttinsert+ 主键/唯
一的索引冲突、直接 insert+主键/唯一的索引冲
突、状态机密等、抽取防重表、token令牌、悲观锁
(如 select for update, 很少用)、乐观说、分布式
锁
技术选型
TODO
技术选型主要比较几个维度:性能、稳定性、接入成本、社区活跃度、业务扩展性、业务特点等等,没有所谓最好的框架/工具,只有最合适自己的。
HTTP 流量的录制工具主要是做什么用呢
TODO
HTTP 流量录制会涉及到一些登陆态的处理吗
TODO
微信朋友圈设计,朋友圈可见与不可见
TODO
埋点如何设计
TODO
实现百度翻译接口,已获得链接和密钥
TODO
二级计算器
TODO
策略模式
100百只箭、A、B交替射箭,每次可以射出1、2个,最后一个射出的人获胜,问如何保证A一定能赢
TODO
如何实现广告的自算收入和三方收入校正
TODO
从数据库取许多记录每行记录包括id,dad_ id,把这些记录转化为tree。
TODO