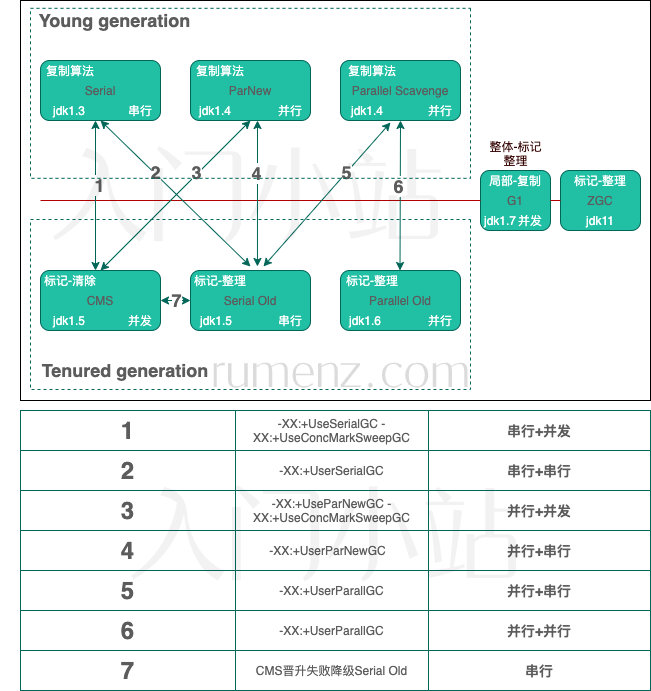
CMS
ConcurrentMarkSweep(并发标记清除)
CMS垃圾收集器从jdk1.6中开始应用,是一个老年代垃圾收集器,在JVM的发展过程中扮演了重要的历史作用,jdk1.7,jdk1.8中都可以开启使用。在jdk9中已废弃。
当出现消费者对某条消息重复消费的情况时,重复消费的结果与消费一次的结果是相同的,并且多次消费并未对业务系统产生任何负面影响,那么这个消费者的处理过程就是幂等的。
在互联网应用中,尤其在网络不稳定的情况下,MQ的消息有可能会出现重复。如果消息重复会影响业务处理,则需要对消息做幂等处理。
消息重复的场景如下:
发送时消息重复
当一条消息已被成功发送到服务端并完成持久化,此时出现了网络闪断或者客户端宕机,导致服务端对客户端应答失败。 如果此时生产者意识到消息发送失败并尝试再次发送消息,消费者后续会收到两条内容相同但Message ID不同的消息。
投递时消息重复
消息消费的场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答的时候网络闪断。为了保证消息至少被消费一次,消息队列RocketMQ版的服务端将在网络恢复后再次尝试投递之前已被处理过的消息,消费者后续会收到两条内容相同并且Message ID也相同的消息。
负载均衡时消息重复(包括但不限于网络抖动、Broker重启以及消费者应用重启)
当消息队列RocketMQ版的Broker或客户端重启、扩容或缩容时,会触发Rebalance,此时消费者可能会收到少量重复消息。
业务操作之前进行状态查询
消费端开始执行业务操作时,通过幂等id首先进行业务状态的查询,如状态已为最终状态(如已出库/已取消),则直接ack
乐观锁
每个数据都有一个版本号,和当前版本号相同时进行更新操作
去重表(缓存)
唯一索引,如果已存在值,就不进行更新了
来源:
RabbitMQ 是流行的开源消息队列系统。RabbitMQ 是 AMQP(Advanced Message Queuing Protocol)的标准实现。
RabbitMQ 采用 Erlang 语言开发。Erlang 是一种面向并发运行环境的通用编程语言。
异步消息传递
支持多种消息传递协议、消息队列、传递确认机制,灵活的路由消息到队列,多种交换类型;
开发人员体验
可在许多操作系统及云环境中运行,并为大多数流行语言提供各种开发工具;
分布式部署
支持集群模式、跨区域部署,以满足高可用、高吞吐量应用场景;
企业和云就绪
可插拔身份认证授权,支持 TLS(Transport Layer Security)和 LDAP(Lightweight Directory Access Protocol)。轻量且容易部署到内部、私有云或公有云中;
工具和插件
支持连续集成、操作度量和集成到其他企业系统的各种工具和插件阵列。可以插件方式灵活地扩展 RabbitMQ 的功能。
管理与监控
有专门用于管理和监督的 HTTP-API、命令行工具和 UI;
综上所述,RabbitMQ 是一个“体系较为完善”的消息代理系统,性能好、安全、可靠、分布式,支持多种语言的客户端,且有专门的运维管理工具。
消息队列RocketMQ版是阿里云基于Apache RocketMQ构建的低延迟、高并发、高可用、高可靠的分布式“消息、事件、流”统一处理平台,面向互联网分布式应用场景提供微服务异步解耦、流式数据处理、事件驱动处理等核心能力。
消息队列RocketMQ版具备海量吞吐的流式存储能力,可以有效对接日志收集、数据集成和数据分析等系统。通过消息队列RocketMQ版可以将上游数据分发到下游的实时计算、离线存储等系统。
消息队列RocketMQ版可以结合事件总线EventBridge轻松实现事件驱动新模式,消息数据经过事件总线EventBridge的可视化事件规则,驱动下游函数计算、HTTP接口、第三方自定义等数据目标。
DeadLine驱动开发,给定一个截止日期,只要在这个DL之前完成即可。
DL驱动开发只追求短期的业务目标,不关注程序设计,缺乏过程管理,程序难以扩展维护。
针对需求进行数据库表设计,再通过数据流串联对应的业务流程,是最常用的软件设计方式,基本可以应对大多数的应用服务场景。
随着系统越来越庞大,传统的软件设计方式已经不能满足我们应对复杂系统的设计。而DDD由业务为导向,通过领域建模限定边界,提供了应对大型复杂系统与业务的方法论。
| 方案一 数据模型驱动 | 方案二领域模型驱动 | |
|---|---|---|
| 优点 | 开发成本相对较低,可部分复用原代码 更好的可读性,新人易上手 有成熟的解决方案,可借鉴经验多 |
业务导向,领域模型优先,边界规范易维持 核心业务逻辑内聚于领域内,易于长期维护 领域模型能更准确的反映业务模型 |
| 缺点 | 数据库优先,贫血模型,不能准确反映业务 面向过程,功能逻辑易分散 业务模块问易产生依赖,边界不易维持 |
前期学习成木高 代码改动量大,开发成本高 新人不易接手 可借鉴经验少 |
使用索引可以加快查询速度,其实上就是将无序的数据变成有序(有序就能加快检索速度)
索引的本质:索引是数据结构。
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
MySQL的数据是存储在硬盘的,在查询时一般是不能「一次性」把全部数据加载到内存中
红黑树是「二叉查找树」的变种,一个Node节点只能存储一个Key和一个Value
B和B+树跟红黑树不一样,它们算是「多路搜索树」,相较于「二叉搜索树」而言,一个Node节点可以存储的信息会更多,「多路搜索树」的高度会比「二叉搜索树」更低。
了解了区别之后,其实就很容易发现,在数据不能一次加载至内存的场景下,数据需要被检索出来,选择B或B+树的理由就很充分了(一个Node节点存储信息更多(相较于二叉搜索树),树的高度更低,树的高度影响检索的速度)
B+树相对于B树而言,它又有两种特性。
在MySQL InnoDB引擎下,每创建一个索引,相当于生成了一颗B+树。
如果该索引是「聚集(聚簇)索引」,那当前B+树的叶子节点存储着「主键和当前行的数据」
如果该索引是「非聚簇索引」,那当前B+树的叶子节点存储着「主键和当前索引列值」
比如写了一句sql:select * from user where id >=10,那只要定位到id为10的记录,然后在叶子节点之间通过遍历链表(叶子节点组成的链表),即可找到往后的记录了。
由于B树是会在非叶子节点也存储数据,要遍历的时候可能就得跨层检索,相对麻烦些。
基于树的层级以及业务使用场景的特性,所以MySQL选择了B+树作为索引的底层数据结构。
对于哈希结构,其实InnoDB引擎是「自适应」哈希索引的(hash索引的创建由InnoDB存储引擎引擎自动优化创建,我们是干预不了)
默认情况下,如果程序中显式的调用
Sysytem.gc()或者Runtime.getRuntime.gc()可能会触发 Full GC,垃圾收集器会同时新生代和老年代进行垃圾回收操作,尝试释放被丢弃对象占用的内存资源。但是调用Sysytem.gc()不一定会发生 Full GC,所以它无法保证对垃圾收集器的调用。
1 | public final class System { |
最终程序调用的是一个本地方法
gc(),垃圾回收的工作是交给操作系统完成的Java 中垃圾回收是自动进行的,因此并不推荐通过调用
Sysytem.gc()来决定 JVM 的 GC 操作。