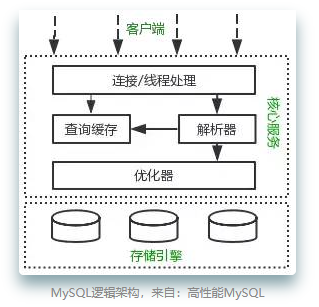
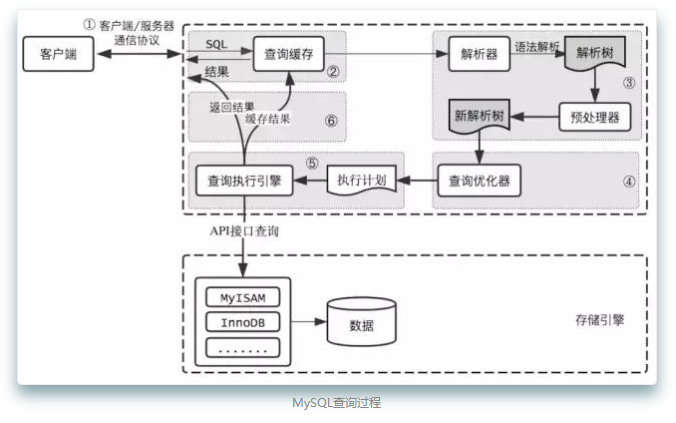
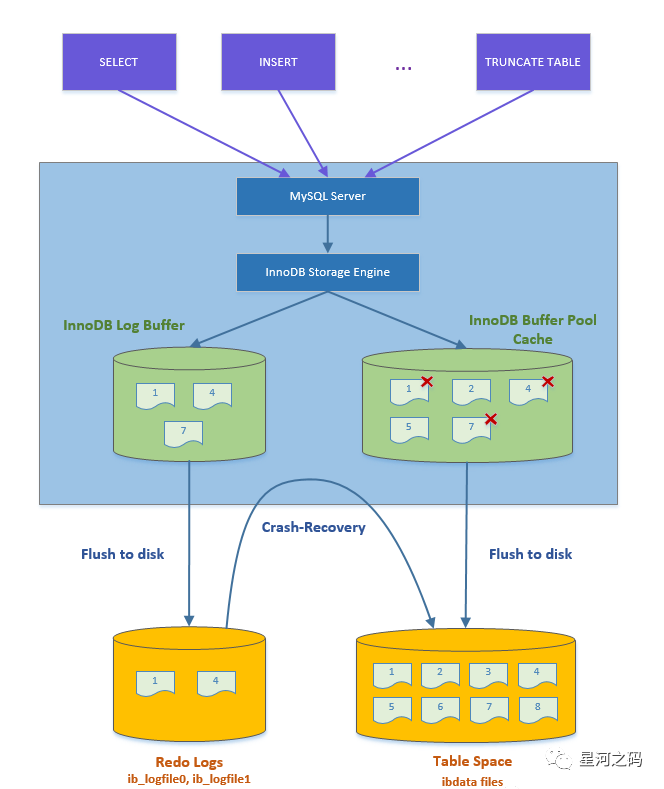
锁
全局锁(数据库只读)
- FTWRL
- 执行:
flush tables with read lock
执行后数据库处于只读状态,对数据的增删改查操作(select、insert、update、delete)以及对表结构的更改操作(alter table、drop table)都会被阻塞
- 执行:
unlock tables
释放全局锁,或者断开会话自动释放全局锁
- 主要应用于做全库逻辑备份,保证备份文件不会因备份期间数据库的更改而与预期不一致。
数据量大的时候会导致业务受影响,因为数据库处于只读状态。因此可以利用MVCC的机制,在备份前开启事务,生成Read View进行保证可重复读,这样备份期间仍然可以对数据库进行增删操作,前提是数据库存储引擎支持事务(数据库只读,MVCC)
表级锁
表锁
| 语句 |
锁类别 |
用途 |
| lock tables t read |
表锁,读锁,共享锁 |
表共享锁之间不互斥,读读可以并行 |
| lock tables t write |
表锁,写锁,排他锁 |
表排他锁与任何锁都互斥,读写/写写都不可并行 |
- 表锁除会限制别的线程读写外,也会限制当前线程后续的读写操作。即对表 t 加了【共享表锁】。当前线程及其他线程的后续写操作会被阻塞直至锁被释放
元数据锁(MDL)
- 对数据库表进行CRUD操作时会自动加MDL读锁 – 读锁
- 对数据库表结构进行变更操作时会自动加MDL写锁 – 写锁
- MDL在事务提交后才会释放。在事务未提交前执行数据库表操作可能会导致数据库线程爆满。
如:线程A在执行selct操作时会自动持有MDL读锁,此时线程B执行数据库表结构变更,则需要获取MDL 写锁,但由于事务未提交,读锁未释放,线程C获取写锁会被阻塞,进入队列等待。队列中【写锁获取优先级大于读锁】,一旦出现写锁等待,会阻塞后续的读锁获取,及阻塞其他的CURD操作线程
意向锁(InnoDB)
意向锁是表级锁,不会和行级锁发生冲突,并且意向锁之间也不会发生冲突。
只会和共享表锁、独占表锁发生冲突
普通的select操作利用MVCC实现一致性读,是【无锁】的
| 加锁方式 |
规则 |
锁类别 |
| select … lock in shard mode |
先对表加上【意向共享锁】,再对读取的记录加上【排它锁】 |
意向锁,共享锁(S),排他锁 |
| select … for update |
先对表加上【意向排他锁】,再对读取的记录加【排它锁】 |
意向锁,排他锁(X) |
执行插入、更新、删除操作前,需要先对表加上【意向共享锁】,再对记录加【排它锁】
表锁和行锁之间满足【读读共享】、【读写互斥】、【写写互斥】
如果没有【意向锁】,那么加【排他表锁】时需要遍历表里的所有记录,查看是否有记录存在【排它锁】,效率会很慢。
有了【意向锁】之后,由于在对记录加排他锁之前,先会加上表级别的【意向排它锁】,那么在对记录加【排他锁时】,直接查看该表是否存在【意向排他锁】即可
| 锁类型 | 用途 |
| 意向排他锁(IX) | 一个事务想给一个数据行加排他锁之前,必须先获得该表的IX锁 |
| 意向共享锁(IS) | 一个事务给一个数据行加共享锁之前,必须先获得该表的IS锁 |
| 当另外事务想给该表加表锁(S锁 或 X锁)时,只需查看该表上的IS锁和IX锁的加锁情况即可,不用再做遍历行锁的行为 |
AUTO-INC锁
行级锁
Record Lock(记录锁)
- 仅仅锁住索引记录的一行,也叫行锁;
- 锁住的永远是索引记录而非记录本身。
- 行记录锁是作用在索引记录(Key)上的锁。(B+树上的Key节点)
Gap Lock(间隙锁,前开后开)
锁加在不存在的空闲空间,可以是两个索引记录之间,也可能是第一个索引记录之前或最后一个索引之后的空间(可重复读级别下才会有间隙锁)
当我们用范围条件而不是相等条件索引数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”。
InnoDB也会对这个“间隙”枷锁,这种锁机制就是所谓的间隙锁(Next-Key锁)
间隙锁定之间不存在冲突关系如果一个事务对某个间隙中间加了锁,那么其他事务也可以在这个间隙中加锁,这些操作不冲突。它的存在,仅仅是为了防止其他事务在这个间隙中插入记录。
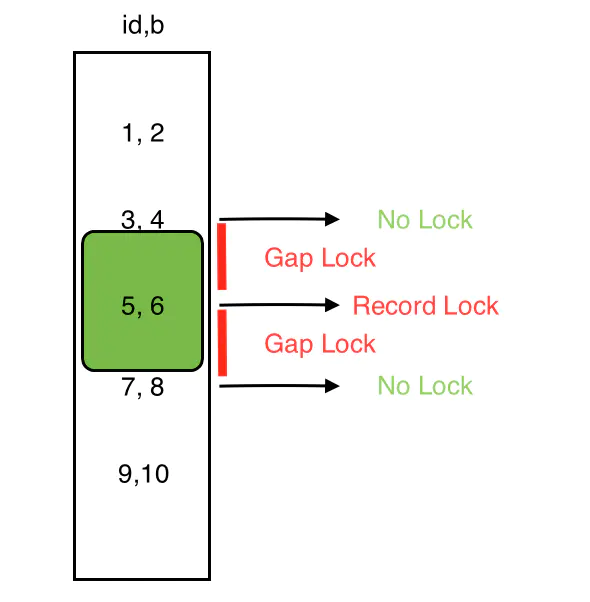
【前开后开】区间
- Insert Intention Lock(插入意向锁)
- 多个事务,在同一个索引,同一个范围区间插入记录时,如果插入的位置不冲突,不会阻塞彼此。
- 插入意向锁 与 间隙锁/临键锁 是会冲突的,并发了会互相阻塞。
- 不加插入意向锁,会 破坏间隙锁保护数据的隔离性。因为检测不到插入动作的冲突
Next-Key Lock(前开后闭)
锁与事务关系
| 锁操作 | 锁处理 |
| 加锁 | 在事务中,随着执行的SQL,按需获取锁。
过程中可能会有阻塞等待或死锁 |
| 释放锁 | 事务提交时,自动释放本事务中所有的锁 |
死锁
概念
死锁的发生:多个事务,每个事务都已持有部分锁,然后进一步去获取对方事务持有的锁,互相等待。
死锁检测和处理
| 参数 |
作用 |
| innodb_lock_wait_timeout |
设置锁超时时间,默认50秒 |
| innodb_deadlock_detect |
开启死锁检测,在检测到死锁时回滚两条中的某一个事务(默认值on) |
正常情况下采用第二种策略。主动死锁检测在发生死锁的时候,是能够快速发现并进行处理的。
如何减少死锁
来源:
https://dev.mysql.com/doc/refman/5.6/en/innodb-locking.html#innodb-intention-locks
https://cloud.tencent.com/developer/article/1806998