方法论
一、微服务架构
1.一组小的服务
2.独立的进程
3.轻量级通信
4.基于业务能力
5.独立部署
6.无集中式管理
二、微服务的利弊
1.利:
1)强模块化边界
2)可独立部署
3)技术多样性
2.弊:
1)分布式复杂性
2)最终一致性
3)运维复杂性
4)测试复杂性
IOC:控制反转,传统使用对象的时候,对象时由使用者控制的,有了Spring之后,可以将整个对象交给容器来帮我们进行管理
DI:依赖注入,将对象的属性注入到具体的对象中,通过@Autowired、@Resource、populateBean方法来完成注入
容器:负责存储对象,使用map结构存储对象,在Spring中存储对象的时候一般有三级缓存:
SingletonObjects存放完整对象、earlySingtonObjects存放半成品对象,SingletonFactory用来存放lambda表达式和对象名称的映射,整个bean的生命周期,从创建到使用到销毁,各个环节都是容器帮我们控制的。
Spring中所有bean都是通过反射生成的,constructor,newInstance,在整个流程中还包含很多扩展点,比如有两个非常重要的接口,BeanFactoryProcessor,BeanPostProcessor,用来实现扩展功能,aop就是在ioc基础之上的一个扩展实现,是通过BeanPostProcessor实现的,Ioc中除了创建对象之后还有一个重点的点就是填充属性

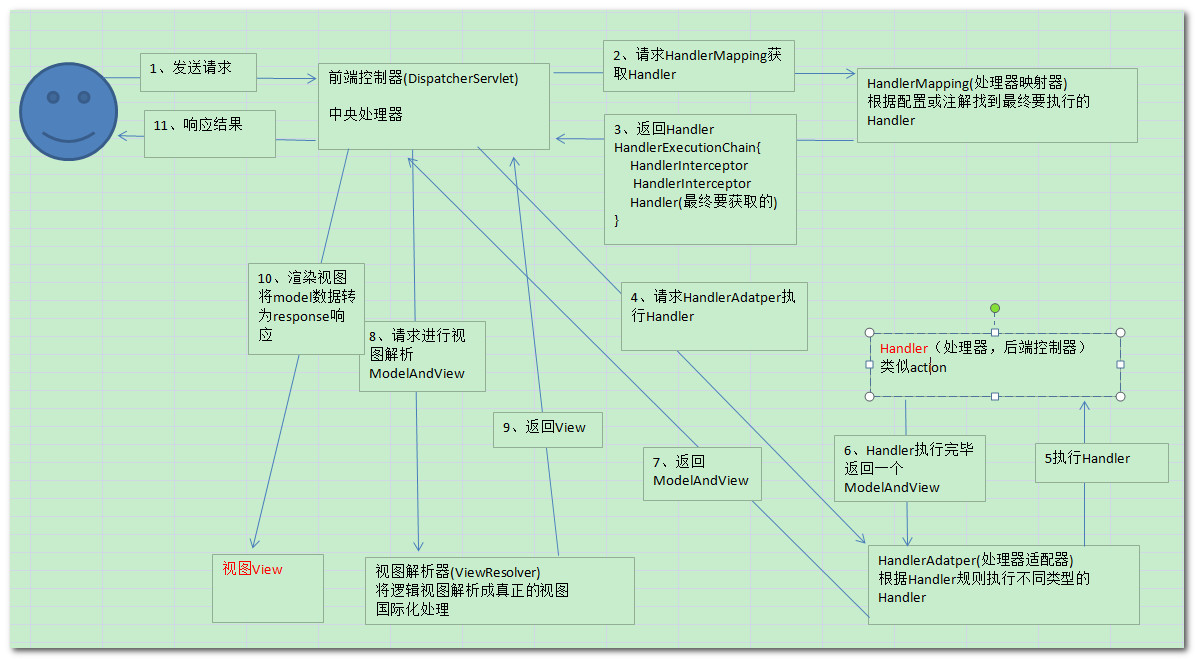
1.用户发送请求至前端控制器DispatcherServlet
2.DispatcherServlet收到请求对URL进行解析,调用HandlerMapping处理器映射器
3.处理器映射器找到具体的处理器,生成处理器对象以及处理器拦截器,一并返回给DispatcherServlet
4.DispatcherServlet调用HandlerAdapter处理器适配器
5.HandlerAdapter经过适配调用具体的处理器(Controller)
6.Controller执行完成返回ModelAndView
7.HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet
8.DispatcherServlet将ModelAndView传给ViewReslover视图解析器
9.ViewReslover解析后返回具体View
10.DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)
11.DispatcherServlet响应用户
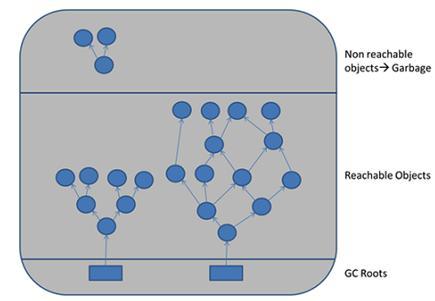
枚举根节点,做可达性分析
JVM中没有使用
在创建对象和将对象赋值给某个变量时,将对象的引用计数+1,在移除对象和某个变量的引用关系时,将对象的运营计数-1,当对象的引用计数变为0时,递归地将该对象引用的子对象的引用计数器减1,并把该对象的内存块加入空闲链表中。在通过增减对象的引用计数器来判别活跃对象和非活跃对象,然后在计数器值为0的时候回收对象,这种做法可以在对象不活跃的时候立即回收它。
优点
缺点
-Xms堆初始值
默认值:物理内存的1/64(<1GB)
-Xmx
堆最大值,默认值:物理内存的1/4(<1GB)
-Xmn
新生代堆最大可用值,一般设置为整个堆的1/3-1/4
新生代大小官网推荐的大小是3/8, 如果设置太小,比如1/10会导致Minor GC 与Major GC次数增多。
-XX+PrintGC
每次处罚GC的时候打印相关日志
-XX:SurvivorRatio
设置新生代中eden区和from/to空间的比例关系n/1
-XX:MaxTenuringThreshold=n
其中 n 的大小为区间为 [0,15], 如果高于 15,JDK7 会默认 15,JDK 8 会启动报错
In Java, there are special objects called Garbage Collection Roots (GC roots). They serve as a root objects for Garbage Collection marking mechanism (see picture).
Classloaders, effectively - via other GC roots.
GC Root对象java虚拟机栈引用对象
方法区类的静态成员引用的对象static variables
方法区常量引用的对象
java native方法栈中JNI引用对象JNI references
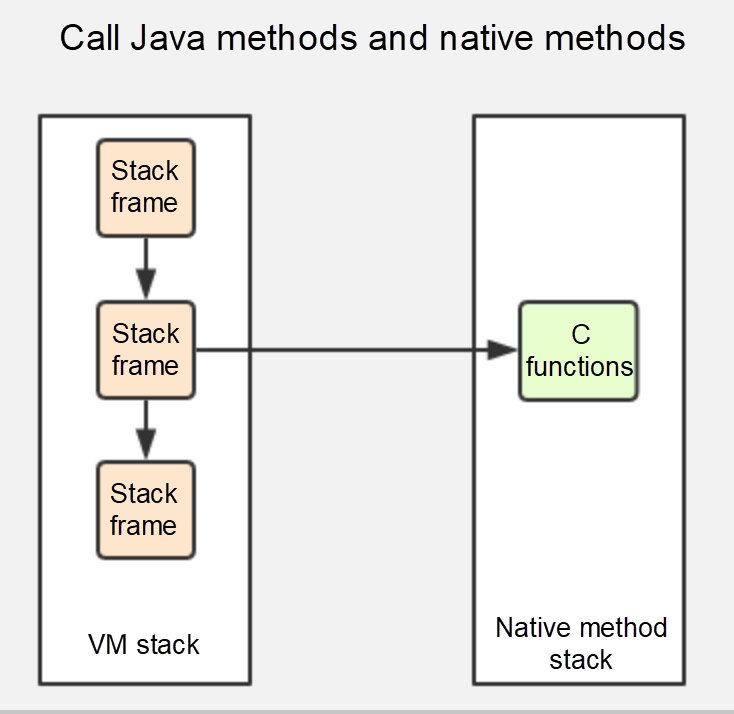
本地方法就是一个 java 调用非 java 代码的接口,该方法并非 Java 实现的,可能由 C 或 Python等其他语言实现的, Java 通过 JNI 来调用本地方法, 而本地方法是以库文件的形式存放的(在 WINDOWS 平台上是 DLL 文件形式,在 UNIX 机器上是 SO 文件形式)。通过调用本地的库文件的内部方法,使 JAVA 可以实现和本地机器的紧密联系,调用系统级的各接口方法
当调用 Java 方法时,虚拟机会创建一个栈桢并压入 Java 栈,而当它调用的是本地方法时,虚拟机会保持 Java 栈不变,不会在 Java 栈祯中压入新的祯,虚拟机只是简单地动态连接并直接调用指定的本地方法。
synchronized锁引用对象
类元
JMXBean
https://rumenz.com/rumenbiji/what-is-gc-roots.html
https://stackoverflow.com/questions/27186799/what-are-gc-roots-for-classes